2.4.2访问
按序号访问成员
|
|
A |
B |
|
1 |
[a,b,c,d,e,f,g] |
|
|
2 |
=A1(2) |
=A1.m(2) |
|
3 |
=A1([2,3,4]) |
=A1(to(2,4)) |
|
4 |
=A1.m(-1) |
|
A2与B2中的表达式是等价的,都是从序列中取出第2个成员,结果如下:
![]()
A3中从序列中取出第2到4个成员,值为序列。注意,[2,3,4]也是个序列(数列),因此B3中中表达式的结果和A3中是相同的:

A4中取出序列中的倒数第1个成员。注意,倒取数时必须用A.m()函数,不能简写为A1(-1)。结果如下:
![]()
特别的,用A.m()函数可以访问多个成员,其中还可以指定某个区间,如:
|
|
A |
B |
|
1 |
[a,b,c,d,e,f,g] |
|
|
2 |
=A1.m(2,-2) |
=A1.m(2:4,3:5) |
|
3 |
=A1.m(-1,4:-2,5) |
=A1.m(-2:2) |
A2中获取序列中的第2个和倒数第2个成员,B2中获取序列中两段区间中的成员,A3中在获取序列成员时,同时使用了指定位置和区间的方式。A2,B2和A3中的结果依次如下:



在指定访问区间时,起始序号不能颠倒,如B3中指定的区间是从倒数第2个到第2个,顺序不正确,获得的结果为空。
如果只需访问序列中的一段区间内的成员,可以使用A.to()函数,如:
|
|
A |
B |
|
1 |
[a,b,c,d,e,f,g] |
|
|
2 |
=A1.to(2,4) |
=A1.to(4,2) |
|
3 |
=A1.to(3) |
=A1.to(-3) |
A2,B2,A3,B3中的结果如下:



出B2的结果中可以看到,与A.m()不同,A.to()函数在指定区间时,可以由后至前,此时获得序列中成员的顺序也是逆序的。A3中表示获得序列的前3个成员,B3中表示获得序列的最后3个成员。
使用A.to()函数,还可以采用平均分段的方式,来获取序列中的某段区间内的成员,如:
|
|
A |
B |
|
1 |
=to(8) |
|
|
2 |
=A1.to@z(1,2) |
=A1.to@z(2,2) |
|
3 |
=A1.to@z(1,3) |
=A1.to@z(2,3) |
|
4 |
=A1.to@z(3,3) |
|
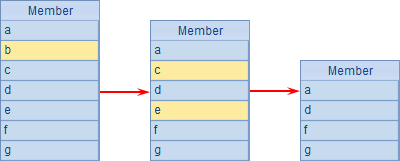
使用A.to@z(i,n)函数,可以将A中的成员平均分为n段,并返回其中的第i段。A2和B2中,将A1中的成员平均分为2段,并分别取出,结果如下:

如果A中的成员数无法平均分段,多余的成员会在最后一组中返回,如A3,B3和A4中结果如下:


A.to@z(i,n)函数是为辅助大数据量运算时的分段统计,这种分段方式能够使得前面n-1段的成员数全部相等,便于统计计算。而当每段成员数量远远大于分段数时,如分为100段,每段100,000个数据,此时最后一组最多也就是100099个成员,与其它组的差异也变得很小了。
赋值和修改
|
|
A |
|
1 |
[a,b,c,d,e,f,g] |
|
2 |
>A1(2)="r" |
|
3 |
>A1([3,4])=["r","s"] |
|
4 |
>A1.modify(4,[ "r","s"]) |
为了明确每个单元格中的语句引起的变化,在这里点击工具栏中的![]() 按钮,分步执行代码。
按钮,分步执行代码。
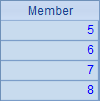
A2将A1中的第2个成员修改为r,A3继续修改A1中的第3、第4个成员。A4从第4个成员起继续依次修改,该表达式等价于>A1([4,5])=["r","s"],逐步运行时A1中序列的变化如下:
新增成员
|
|
A |
|
1 |
[a,b,c,d,e,f,g] |
|
2 |
>A1.insert(0,"r") |
|
3 |
>A1.insert(2,["r","s","t"]) |
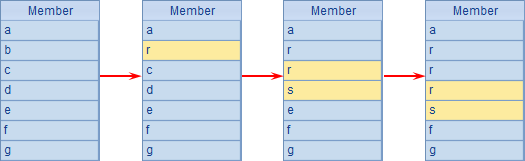
A2在序列结尾新增成员,A3继续在第2个成员之前连续插入3个新成员。仍然使用分步执行,A1中序列的变化如下:
除了insert之外,还可以用A.pad(x,n)函数,在序列A中连续添加x构成新序列,直到其中的成员个数达到n,如:
|
|
A |
|
1 |
[a,b,c,d,e,f,g] |
|
2 |
=A1.pad("A",10) |
计算后,A2中的结果如下:

A1中的原序列不会受到pad函数的影响。
删除成员
|
|
A |
|
1 |
[a,b,c,d,e,f,g] |
|
2 |
> A1.delete(2) |
|
3 |
> A1.delete([2,4]) |
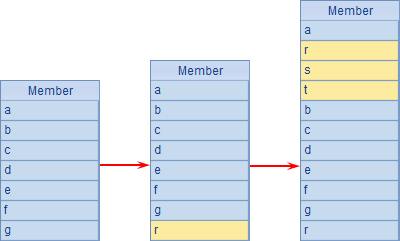
A2中删除第2个成员,A3中继续删除第2、第4个成员,分布执行时,A1中变化如下: