2.4.1生成
常数构造
在显示序列和序表时,在集算器中会显示Index列以便查看,这一列并不属于序列或序表的结构,在后面的展示中,并不一定会显示这一列的内容。
将常数直接用"[]"括起来可表示序列常数,也可以在表达式中用"[]"将成员括起来得到序列,如:
|
|
A |
B |
C |
|
1 |
1 |
red |
2013-06-04 |
|
2 |
2 |
blue |
27.49 |
|
3 |
3 |
yellow |
Tom |
|
4 |
[15.2,b,1] |
=[A1:C3] |
=[3,A4,B4] |
|
5 |
[1,2,3,3] |
[] |
[[]] |
网格中,A4,A5,B5,C5中,都是序列常数,B4和C4中是用表达式计算的序列。
其中,A4序列中的成员包含了浮点数、字符串、整数等不同的类型,B4中的成员由单元格区域得到,C4中序列的成员还包含序列,A5中序列中存在重复的成员。A4,B4,C4和A5中的数据依次如下:



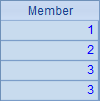
下面来比较一下B5和C5中的值:
![]()
![]()
可以看到,B5中是空序列,而C5中是一个非空序列,其成员只有一个空序列。
说明:序列的成员可以是任意数据类型,包括基本类型、其他序列、记录等等,成员全是整数的序列被称为数列。
函数构造
|
|
A |
|
1 |
=to(2,6) |
|
2 |
="1,a,b,c".split@c() |
|
3 |
=periods@y("2014-08-10",date(now()),1) |
|
4 |
=file("sales.txt").import@t() |
其中A1表示从2到6的连续整数构成的序列,如果从1开始的数列可以简写为to(6)。A2中将字符串拆分为序列。A3中以年为间隔生成两个日期之间的日期序列。A1,A2和A3中的结果如下:


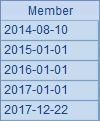
A4从结构化的文本文件中读取记录形成序列,其值为:
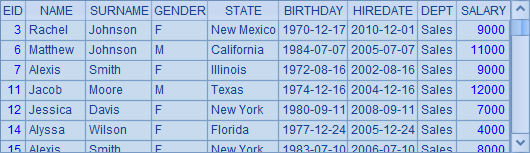
以记录为成员的序列又称作序表,常用来进行结构化数据的计算,序表不是本文重点,想进一步了解请参考2.5使用序表与排列。
计算生成
下面网格中的代码,将文本文件sales.txt读入序表A1,取其中的STATE列,生成序列A2,将记录按照STATE分组,生成序列A3:
|
|
A |
|
1 |
=file("sales.txt").import@t() |
|
2 |
=A1.(STATE) |
|
3 |
=A1.group(STATE) |
计算后,A2中的序列如下:
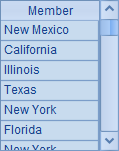
A3中的序列如下:
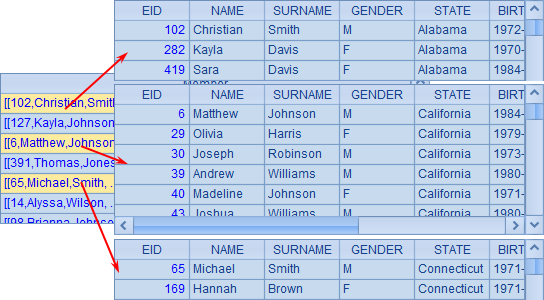
可以看到,序列A3的成员是多个序列,这些序列的成员都是记录。