3.1.4新建与引出的连续使用
在生成新序表时,有时我们需要添加一些计算列,同时并不需要原序表中的其它所有字段,或者需要调整生成序表中字段的顺序。此时可以将new函数和derive函数连续使用。如:
|
|
A |
|
1 |
$(demo) select EID,NAME,SURNAME,BIRTHDAY,GENDER from EMPLOYEE |
|
2 |
=A1.derive(NAME+" "+SURNAME:FullName).new(EID,FullName,GENDER, BIRTHDAY) |
|
3 |
=A1.derive(NAME+" "+SURNAME:FullName) |
|
4 |
=A3.new(EID,FullName,GENDER,BIRTHDAY) |
我们根据A1中,员工的NAME和SURNAME计算出FullName,此时NAME和SURNAME就不再需要了。同时字段的顺序也需要整理,如derive生成的字段总在最后,但是想将FullName前移。因此在A2中,将derive函数与new函数配合使用。A2中结果如下:
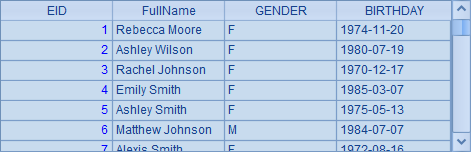
A2相当于A3和A4中分步执行的情况。因此,在连续使用时,new函数实际上是在derive的结果中执行的,如A3中的情况:
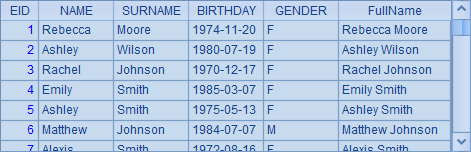
因此在new函数中,可以引用最初序表中的字段如EID,也可以引用derive生成的新字段FullName。
在连续使用时,先用derive函数添加字段,再用new函数整理结果,这样的使用更为常见。但是,先用new函数整理出需要的字段,再用derive函数生成计算字段也是可以的,如:
|
|
A |
|
1 |
$(demo) select EID,NAME,SURNAME,BIRTHDAY,GENDER from EMPLOYEE |
|
2 |
=A1.new(EID,NAME+" "+SURNAME:FullName,GENDER, age(BIRTHDAY):Age).derive(string(Age)+GENDER:Group) |
在这个例子中,Group字段需要使用新增的Age字段来计算,因此在A2中先用new函数初步整理序表,再用derive函数计算Group字段,A2中结果如下:
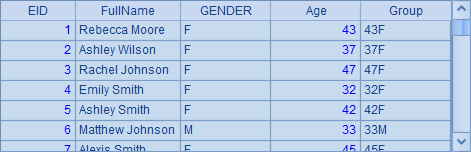
需要明确的是,此时derive函数是在new的结果中计算的,此时不能再引用初始的A1序表中的数据,如NAME,SURNAME等。