4.1.6常见的SQL语句与集算器语法的对照
1. select * from
|
|
A |
|
1 |
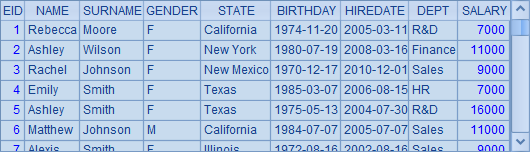
=demo.query("select * from EMPLOYEE") |
查询结果如下:
2. select … from
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.new(EID, NAME, SURNAME, GENDER, BIRTHDAY, DEPT) |
|
3 |
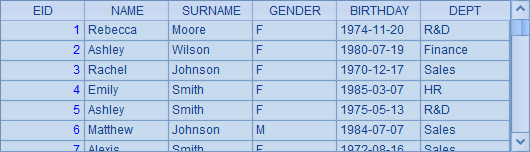
=demo.query("select EID, NAME, SURNAME, GENDER, BIRTHDAY, DEPT from EMPLOYEE") |
从表中取出指定字段,A2与A3中的查询结果是相同的,如下:
3. as
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.new(EID, NAME+" "+SURNAME: FULLNAME, GENDER, age(BIRTHDAY):AGE, DEPT) |
|
3 |
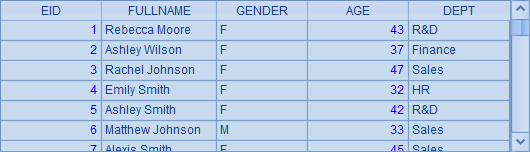
=demo.query("select EID, NAME+' '+SURNAME as FULLNAME, GENDER, year(now())-year(BIRTHDAY) as AGE, DEPT from EMPLOYEE") |
根据名(NAME)和姓(SURNAME)计算出全名(FULLNAME),同时根据生日(BIRTHDAY)计算出年龄(AGE),A2与A3中的查询结果基本是相同的,如下:
需要注意的是,A3中,计算年龄时只是简单用年相减,由于SQL没有直接计算年龄的函数,准确计算会更复杂。
4. where
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.new(EID, NAME+" "+SURNAME: FULLNAME, GENDER, age(BIRTHDAY):AGE, DEPT) |
|
3 |
=A2.select(AGE<35) |
|
4 |
=demo.query("select EID, NAME+' '+SURNAME as FULLNAME, GENDER, year(now())-year(BIRTHDAY) as AGE, DEPT from EMPLOYEE where year(now())-year(BIRTHDAY)<30") |
查询年龄小于35岁的员工,在集算器中,可以利用已有的结果计算,A3中查询结果如下:
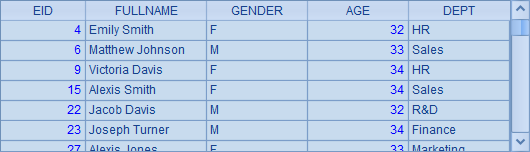
A4中用SQL查询同样的结果,语法就复杂得多,而且在这里由于计算年龄时不精确,因此结果也存在误差。
5. count、sum、avg、max和min
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.new(EID, NAME+" "+SURNAME: FULLNAME, GENDER, age(BIRTHDAY):AGE, DEPT) |
|
3 |
=A2.count(AGE<35) |
|
4 |
=demo.query("select count(EID) from EMPLOYEE where year(now()) - year(BIRTHDAY)-(case when month(now())<month(BIRTHDAY) then 1 WHEN month(now())=month(BIRTHDAY) and day(now())<day(BIRTHDAY) then 1 else 0 end)<35") |
查询年龄小于35岁的员工总数,在集算器中,可以利用已有的结果计算,A3中查询结果如下:
![]()
A4中这次用比较精确的方法来计算年龄,获得的查询结果和A3中的一致,但无法利用已有的结果,而语句也复杂得多。
sum、avg、max和min等SQL函数的使用方法和count基本类似。
6. distinct
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.id(DEPT) |
|
3 |
=demo.query("select distinct DEPT from EMPLOYEE") |
查询员工资料来自哪些部门,A2与A3中结果相同,查询结果如下:

7. order by
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.new(EID, NAME+" "+SURNAME: FULLNAME, GENDER, age(BIRTHDAY):AGE, DEPT) |
|
3 |
=A2.select(AGE<35).sort(-AGE, FULLNAME ).new(FULLNAME, AGE) |
|
4 |
=demo.query("select FULLNAME, AGE from (select NAME+' '+SURNAME as FULLNAME, year(now())-year(BIRTHDAY)-(case when month(now()) < month(BIRTHDAY) then 1 WHEN month(now())=month(BIRTHDAY) and day(now())<day(BIRTHDAY) then 1 else 0 end) as AGE from EMPLOYEE) where AGE<35 order by AGE desc, FULLNAME") |
查询年龄小于35岁的员工,并按照年龄降序排序,同龄员工按全名升序排序,A3与A4中的查询结果相同,如下:
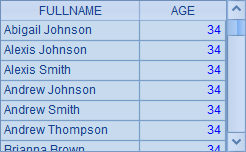
由于SQL中计算年龄比较复杂,而且无法利用已有的结果,A4中这次用嵌套查询来简化语句,但仍然比较复杂。
8. and、or、not和<>
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.new(EID, NAME+" "+SURNAME: FULLNAME, GENDER, age(BIRTHDAY):AGE, DEPT) |
|
3 |
=A2.select(AGE<35&& left(FULLNAME,1)== "S" ).new(FULLNAME, AGE) |
|
4 |
=demo.query("select FULLNAME, AGE from (select NAME+' '+SURNAME as FULLNAME, year(now())-year(BIRTHDAY)-(case when month(now()) < month(BIRTHDAY) then 1 WHEN month(now())=month(BIRTHDAY) and day(now())<day(BIRTHDAY) then 1 else 0 end) as AGE from EMPLOYEE) where AGE<35 and left(FULLNAME, 1)='S'") |
查询年龄小于35岁,且全名的首字母是S的员工,结果如下:
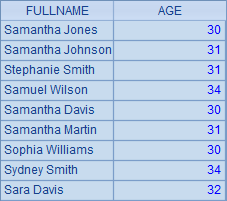
可以看到,集算器中,and使用操作符&&来表示,而且,判断是否相等用两个等号==,这和很多程序语言中的习惯相同。与之类似,在集算器中,or使用操作符"||",not使用操作符"!",<>使用操作符"!="。
9. like
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.select(like(NAME,"*a")).new(NAME+" "+SURNAME:FULLNAME) |
|
3 |
=demo.query("select NAME+' '+SURNAME as FULLNAME from EMPLOYEE where NAME like '%a'") |
查询名字以a结尾的员工的全名,查询结果如下:
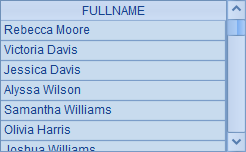
在使用like函数时,不同的数据库,对通配符的使用是不同的,如本例中,用通配符"%"来表示零个或多个任意字符,而在某些数据库中,要用通配符"*";而用集算器来处理的话,对任何数据库,语法都是统一的。
10. group
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.new(NAME+" "+SURNAME: FULLNAME, DEPT).group(DEPT) |
|
3 |
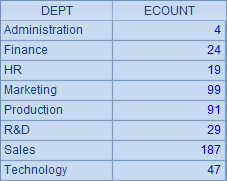
=A1.groups(DEPT;count(~):ECOUNT) |
|
4 |
=demo.query("select DEPT, count(*) as ECOUNT from EMPLOYEE group by DEPT order by DEPT") |
根据员工所在部门分组,在集算器中,可以用group函数对记录分组,如下:
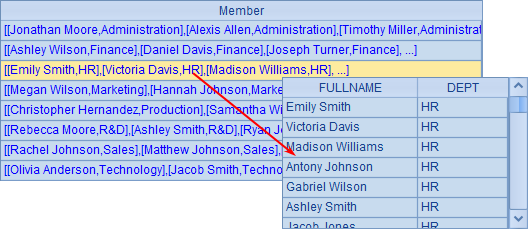
可以看到,用集算器分组的结果,就是把记录分成了若干个组。利用分组的结果,在集算器中还可以根据需要继续计算。
A3中用集算器函数直接计算分组汇总,A4用SQL计算分组汇总,它们的结果是相同的。在SQL中,其实并没有真正的“组”的概念,只能在查询中,根据分组直接聚集计算。结果如下: