4.1.5利用SQL的查询结果
在集算器中,可以利用SQL的查询结果,进行过滤、排序、组合等等操作,以提高查询效率,或者解决一些比较复杂的问题。
下面的例子都是在数据源管理器中连接demo数据源,基于A1格中的查询结果做的:
|
|
A |
|
1 |
=demo.query("select * from STATES order by POPULATION desc") |
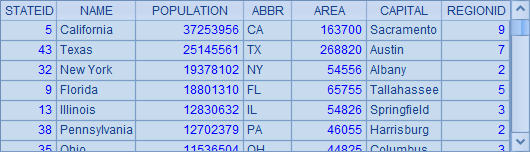
如,对数据过滤,检索指定缩写的州数据:
|
|
A |
|
1 |
=demo.query("select * from STATES order by POPULATION desc") |
|
2 |
[CA,ME,NM,SC,LA] |
|
3 |
=A1.select(A2.pos(ABBR)>0) |
|
4 |
=A1.select(A2.contain(ABBR)) |
A3中用A2.pos(ABBR)>0来判断一个州的缩写是否在制定序列中。判断某个数据是否是指定序列的成员,也可以用A.contain(x) 函数,A3和A4中的表达式是等价的,运算结果也是相同的,如下:
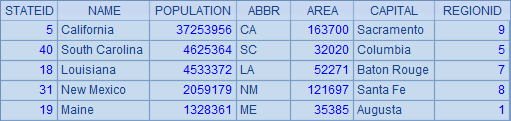
还可以对数据聚合计算,如统计缩写以C开头的州共有多少个:
|
|
A |
|
1 |
=demo.query("select * from STATES order by POPULATION desc") |
|
2 |
=A1.count(left(ABBR,1)=="C") |
![]()
更有意义的,就是对数据库数据按要求分组,如按照缩写的首字母分组:
|
|
A |
|
1 |
=demo.query("select * from STATES order by POPULATION desc") |
|
2 |
=A1.group(left(ABBR,1)) |
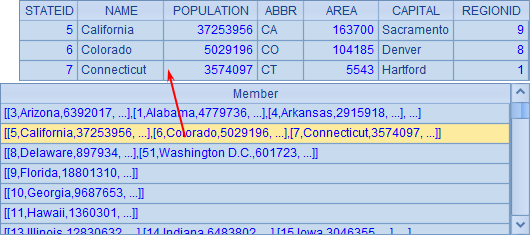
A2按照每个州缩写的首字母分组,其中每一组的数据,都可双击查看内容。
可见,与SQL中未分组汇总服务的“分组”不同,在集算器中对数据的分组是真正的分组,可以在此基础上进行更多的计算。如选出组内州大于等于3个的,计算这些组内的州总数及总人口:
|
|
A |
|
1 |
=demo.query("select * from STATES order by POPULATION desc") |
|
2 |
=A1.group(left(ABBR,1)) |
|
3 |
=A2.select(~.count()>=3) |
|
4 |
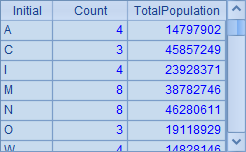
=A3.new(left(ABBR,1):Initial, ~.count():Count, ~.sum(POPULATION):TotalPopulation) |
A4中的最终结果是: