
上一篇我们讲了中国报表的前世今生,是报表工具的第一次革命。是以润乾报表为代表的国产工具创新地实现了非线性模型,解决了中国式复杂报表难题的革命,是让国产报表战胜了国外报表的革命。
这一轮创新后,复杂报表的制表方面的难题就基本都解决了。
然而,我们还是会发现,虽然报表工具已经很强大,什么复杂表格都能做,但有些时候,报表开发还是很让人头疼,感觉做起来没完没了,几乎应用系统的后期都是在做报表。

啥?报表工具还没解决完报表开发问题?
是滴,报表的制作,有两个环节,一个是制作表格,另一个是准备数据。
制作表格的困难是直观的,更容易被感受到,所以设计了报表工具来解决了它。
数据准备则并没有被太关注!
第一次革命:没有注重数据准备

因为大部分报表的数据准备其实并不复杂,一句SQL就搞定了,这时候我们甚至都感觉不到报表还有数据准备这个阶段。当然也就不会觉得它难了。
但数据复杂的时候,数据准备工作就没有那么好做了,难题就来了!一些过程式的多步骤复杂计算,常常需要高级工程师写很长的多层嵌套SQL 或者存储过程或者建个中间表才能搞定,遇到非关系数据库或者文本数据源这些不支持 SQL 的,那还得用 JAVA 等语言来写,SQL 10 几行能写完的,JAVA 恨不得写出几百行来,编码难度和效率就更糟糕了。
手工数据准备费时费力
而且解决这个难题的成本还很高,尤其是在表格可以用工具快速画出,它只能手工艰难编码的情况下,就显得更为突出,这仅占 20% 的需要硬编码来做数据准备的报表,可能会占去我们 80% 的工作量。
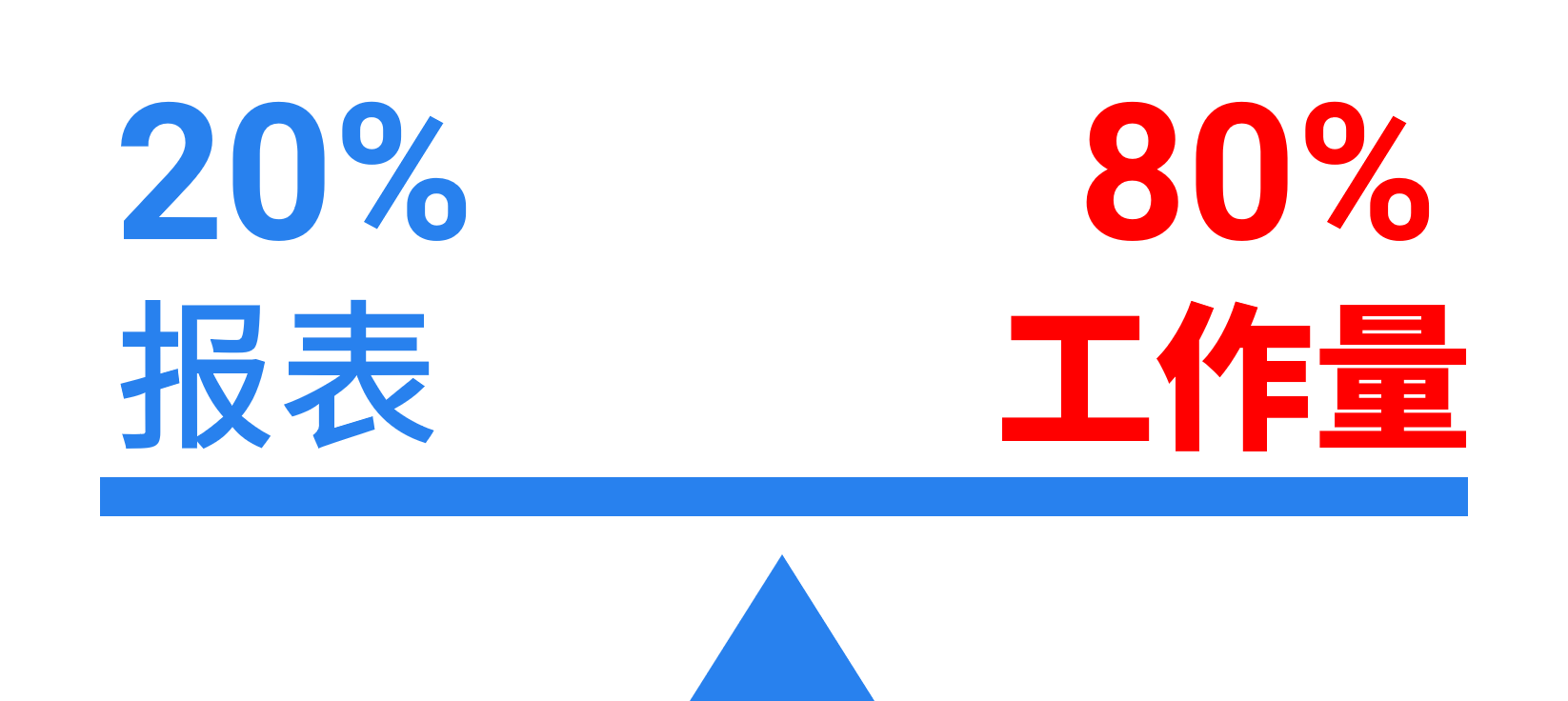
然而,大部分的报表工具,并没能解决这个难题。
当然,有些报表厂商可能会说,这些需要用中间表、存储过程的数据准备工作也不是该报表管的啊,这个锅我不背。
但这个环节做不好,报表就做不出来,给用户的感受就是报表不行!有些锅,不背也得背。
存储过程、JAVA耦合危害大
这些需要用存储过程,中间表,JAVA程序做数据准备的报表,工作量大,开发效率低只是一方面,它们还会带来架构上的问题。
存储过程和中间表会与数据库产生耦合。JAVA程序会与应用产生耦合。
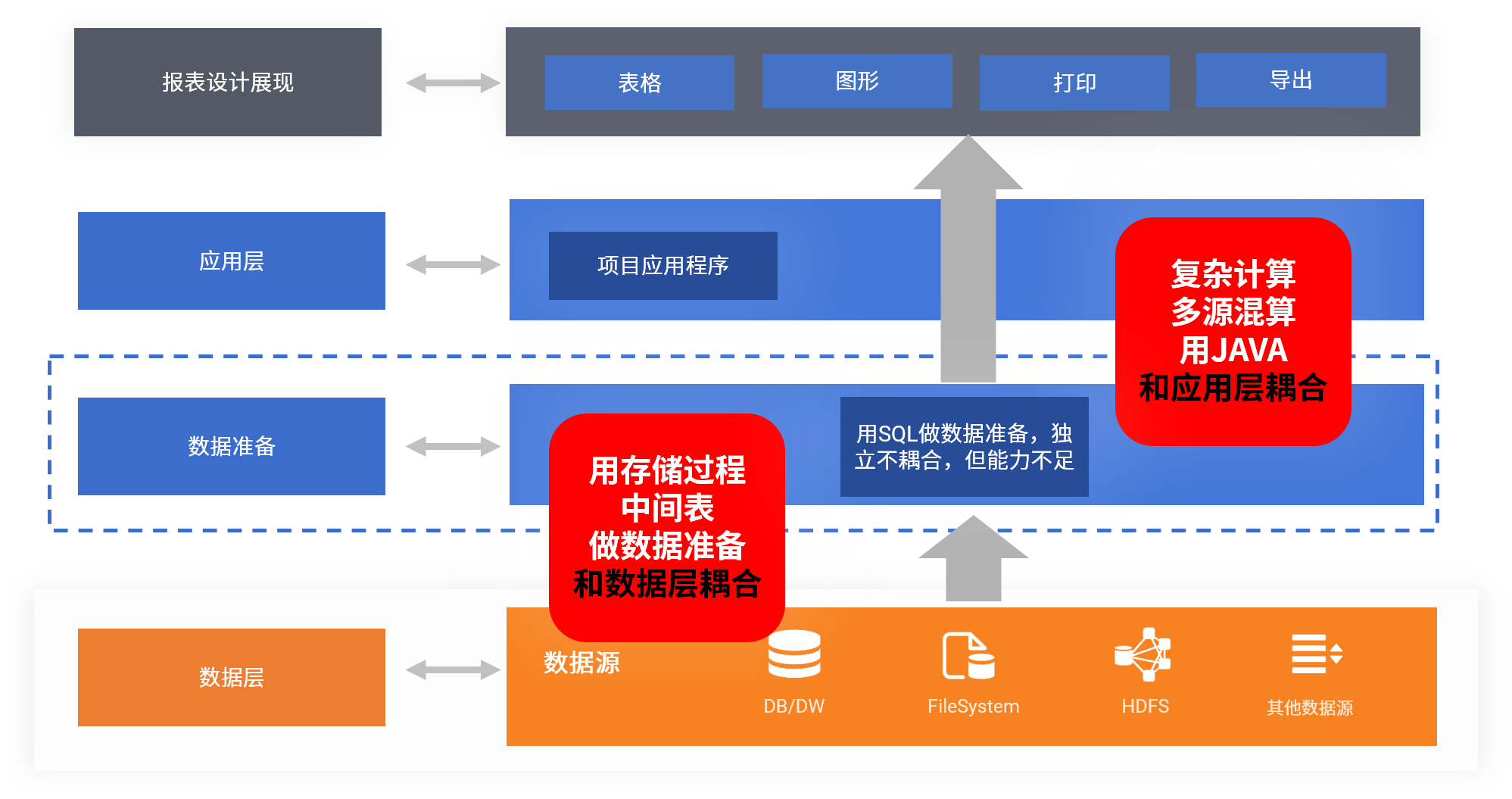
随着系统不断的开发使用,它们会慢慢的累积起来,耦合会越来越严重。危害很大,很要命。
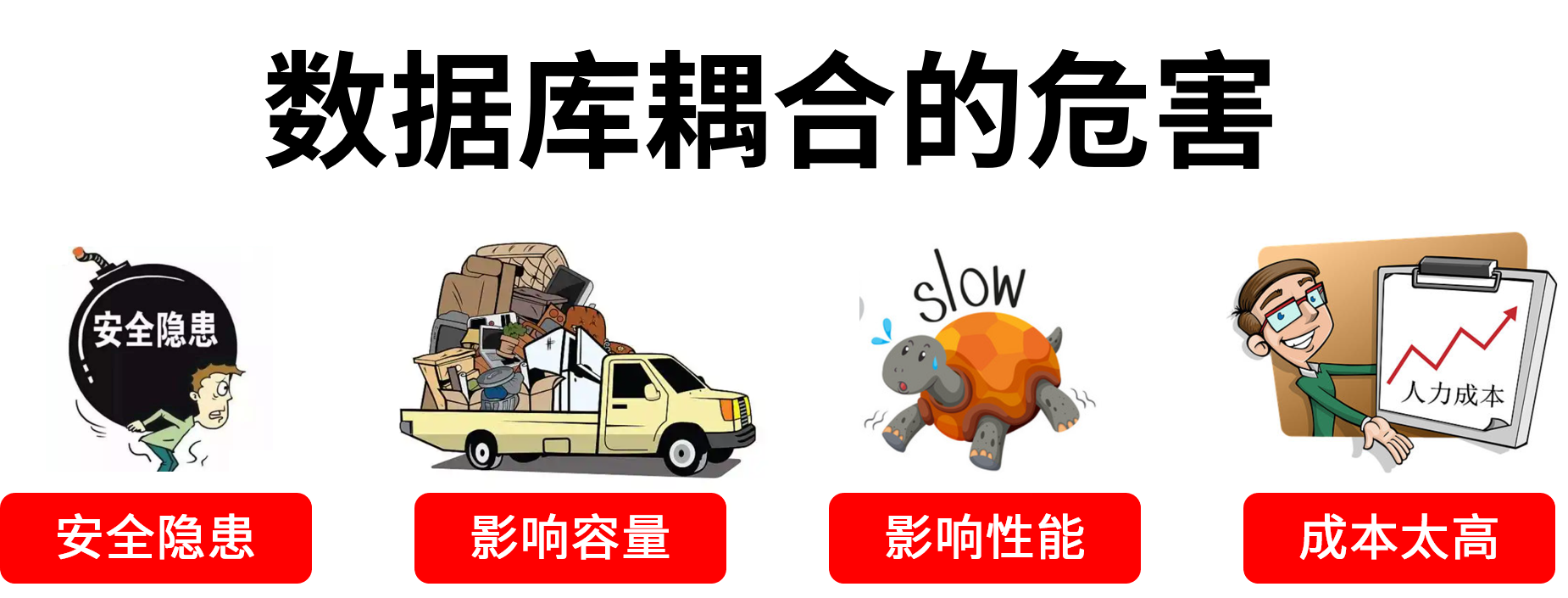
报表开发人员,原本只需要写 SQL做报表,但用到存储过程和中间表,就需要动数据库,就得赋予相应权限,就会有安全风险。
随着时间的推移,这些会变的越来越多,又不好管理,不能随意删除,就只能一直占用着数据库资源,影响容量,满了还得花大价钱扩容。
它们还要计算,甚至有些已经弃用的也仍然在定期计算,会抢占数据库关键业务的计算资源,带来性能问题。
它们一般都需要高级一些的工程师来编写,还有可能麻烦 DBA,人员成本就会变高。
这些都是存储过程和中间表耦合带来的危害。
JAVA程序也会和应用产生耦合,也会带来危害。
JAVA 代码需要和应用一起编译,报表的业务稳定性又低,总得加新的,改旧的,就得总改代码,重新编译,应用就得停机重启,严重影响了服务的持续性,这是很致命的问题。
同样,写 JAVA, 就得 JAVA 人员,成本会更高。
数据准备阶段性能问题堪忧
另外,随着大数据时代的到来,报表的性能问题也变的格外突出。
报表的性能问题,80%都和报表本身无关。
报表的呈现周期中,大致有这4 个环节,它们都有可能造成报表的性能问题,但概率较高、问题较严重的是前两个环节,数据准备和数据传输,而这俩环节又其实和报表工具没多大关系,是报表功能之外的。
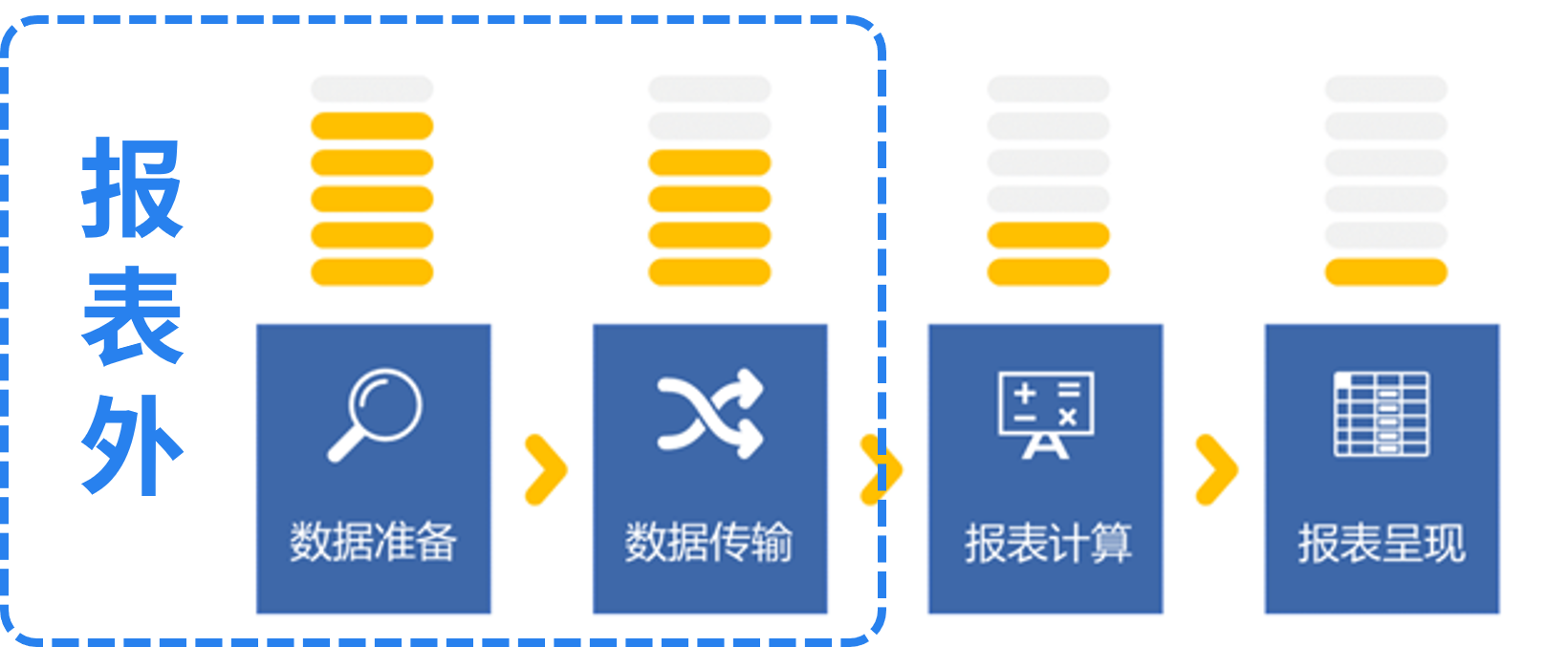
所以这个问题仅仅靠优化报表是无法解决的,需要在数据准备阶段发力才可以。
到这里,我们基本可以看出,后报表工具时代的报表开发问题,主要就是在数据准备阶段。这种原始的只能用手工来做的数据准备,不仅费时费力困难重重,还带来了各种耦合危害和性能问题。
它就像一台半自动洗衣机,只能做一半的工作,剩下的还得手工做,第一次报表革命并不能解决这些问题了。
是时候进行第二次革命性的创新了!

第二次革命:工具代替手工数据准备
增加一个数据准备层,用高效的工具来代替手工做数据准备,就是报表工具需要的二次革命。
这一次,又是润乾,最早注意到这些问题,并在报表工具中增加了数据准备层,使用了更简洁的脚本语言SPL 来代替复杂的大段SQL和JAVA代码,用工具代替了手工。
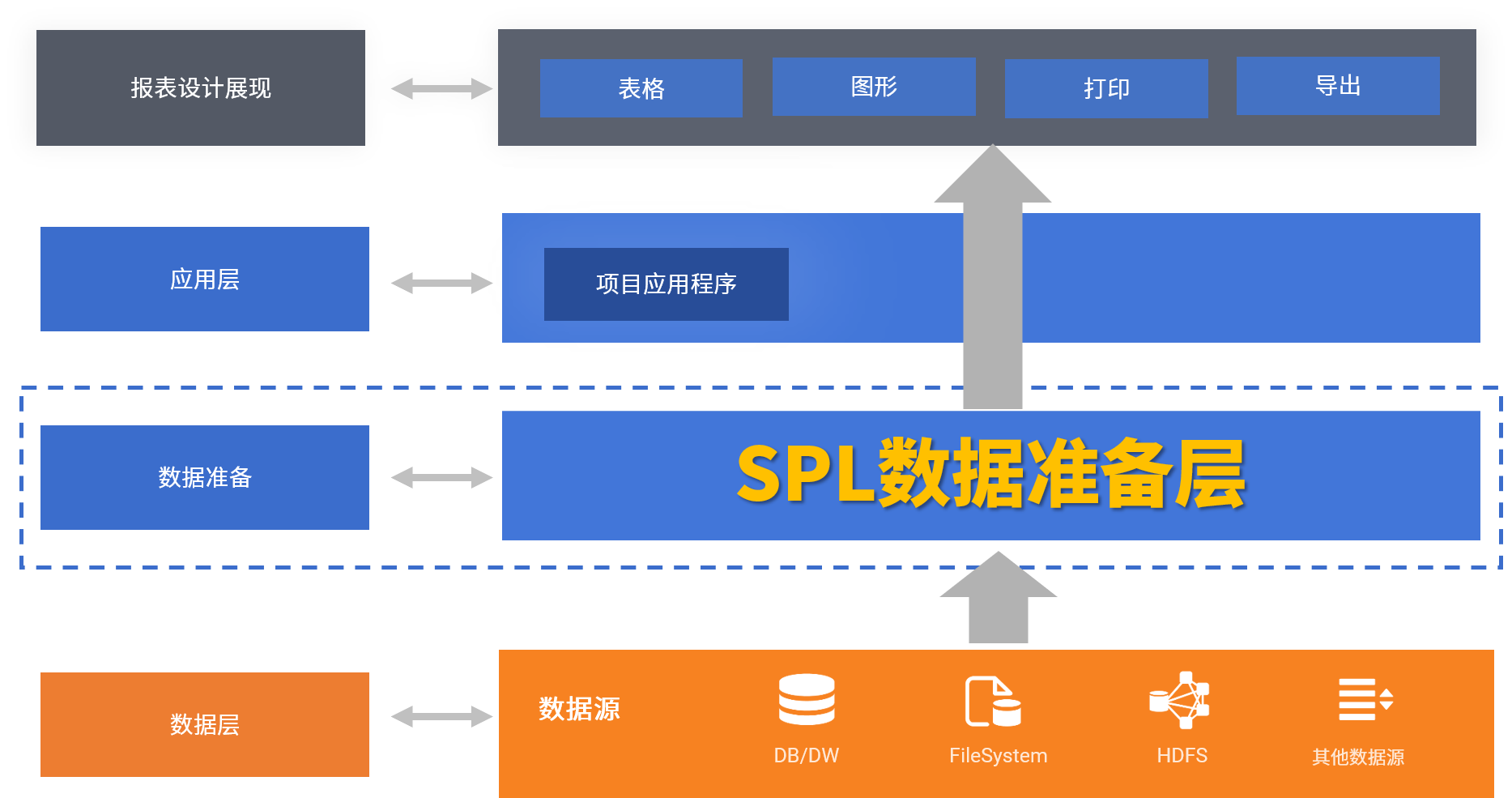
SPL相较于之前手工数据准备具备如下能力和优势。
SPL开发简单
一定要比SQL和JAVA简单才可以,否则就没有意义。
比这些简单,才不用去写大段的复杂SQL和JAVA,才能实现普通人员快速开发。
比如这个例子:报表中需要计算连续上涨超过 5 天的股票及上涨天数。
SQL写起来是这样的,需要三层嵌套
select code,max(risenum)-1 maxRiseDays
from (
select code,count(1) risenum
from(
select code,changeSign,sum(changeSign) over(partition by code order by ddate) unRiseDays
from(
select code,ddate,case when price>=lag(price) over(partition by code order by ddate)
then 0 else 1 end changeSign
from stock_record
)
)
group by code,unRiseDays
)
group by code
having max(risenum) > 5
SQL写的不太好的同学很难写出来,用JAVA来写的话那要再长十几倍,没法列在这里了。
而SPL写出来是这样的
| A | |
| 1 | =db.query("select * from stock_record order by ddate") |
| 2 | =A1.group(code; ~.group@i(price < price[-1]) .max(~.len()):maxrisedays) |
| 3 | =A2.select(maxrisedays>5) |
就简单很多,不仅简短,而且易于理解,初级工程师也能很快学会并写出来,实施成本也能降很多。
大数据时代,报表的数据来源也是多种多样五花八门,很多NOSQL,文本数据根本用不了SQL,报表又需要对它们进行混合计算。

那就只能是先都ETL到数据库,再用SQL算,或者干脆用JAVA来混算了,这就又是老问题,困难低效成本高。
而SPL数据准备层则同样可以轻松解决这些问题,它能直接对接各类数据源,直接对各种格式数据进行计算
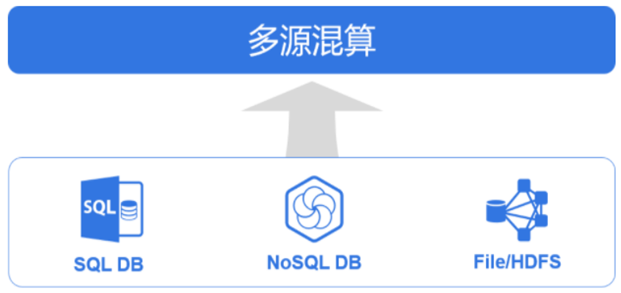
开发过程很简单,比如这个来自HTTP的JSON数据和来自ORACLE数据的混算,SPL五行就可以做完,但JAVA或SQL就不知道得写多长了。
| A | B | |
| 1 | =httpfile(“http://125.125.315.88:6868/orders/order1”:“utf-8”).read() | 读取 Restful 数据 |
| 2 | =json(A1) | 解析数据 |
| 3 | =connect(“oracle”) | 连接 oracle 数据源 |
| 4 | =A3.query@x(“select OrderID, PaymentID, CustomerID, Amount from Payment”) | 从 oracle 取数 |
| 5 | =join(A2:order, OrderID; A4:hk, OrderID) | 关联计算 |
数据准备层让开发变的简单,大大缩短报表的开发周期,还可以让初级工程师搞定高难问题,大大减少了人力成本。
SPL优化架构
存储过程是存在数据库内的,会和数据库发生耦合,但SPL数据准备层不会,因为它是存在数据库外面的,与报表模版存在一起,自然也就不会有存储过程那些安全风险和耦合的问题了。
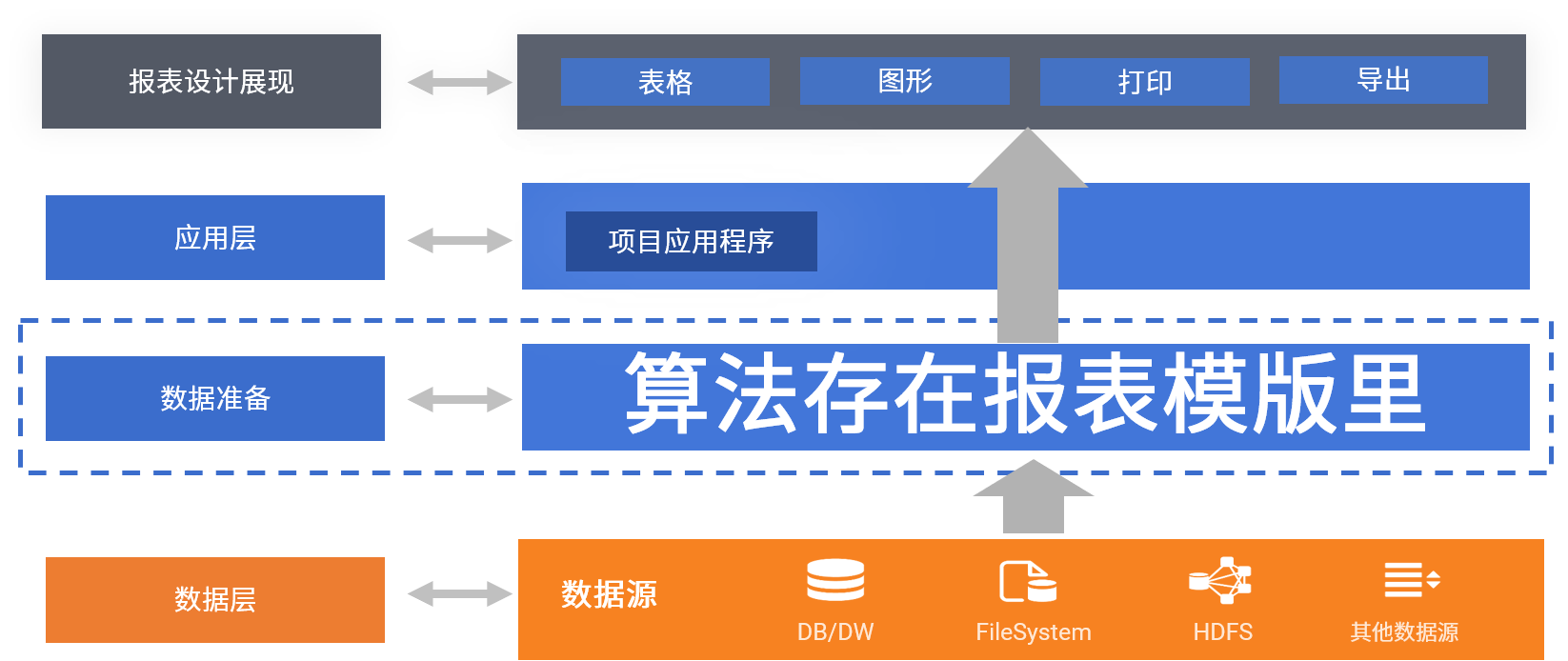
中间表也是,有需要中间数据的报表计算,SPL可以把中间数据存储在数据库外,放到文件系统中,像文件一样去管理,就不用再担心冗余数据占用昂贵的数据库空间了。文件还会比数据库有更好的IO吞吐性能,相关计算也会更快。
数据准备层本身还有计算能力,而且又把存储过程和中间表这些原本占用数据库计算资源的包袱都卸掉了,这样报表的计算大部分就放到库外了,数据库就可以去做更重要的关键业务计算了,不会被报表影响了。
除了能解耦数据库,释放数据库资源,SPL数据准备层还能解耦应用,因为它基本可以取代JAVA了,它写出来的脚本也是类似报表模板的外置文件

不需要和主应用程序一起编译打包,而且它是解释执行的动态语言,在修改时不会涉及主应用程序,只要把脚本替换就可以,天然就支持热切换。
优化架构后,就可以大幅度减少系统维护的工作,节省出更多的人工成本。
SPL提升性能
数据准备层还对于报表性能的提升有很大帮助。
SPL数据准备层采用全新的算法,比SQL的算法更高效,很多场景都比SQL算的要快很多。

大数据量的情况下,有些数据库的 JDBC 取数太慢,会导致了性能问题,SPL则可以通过并行取数方式数倍提升数据的传输性能。
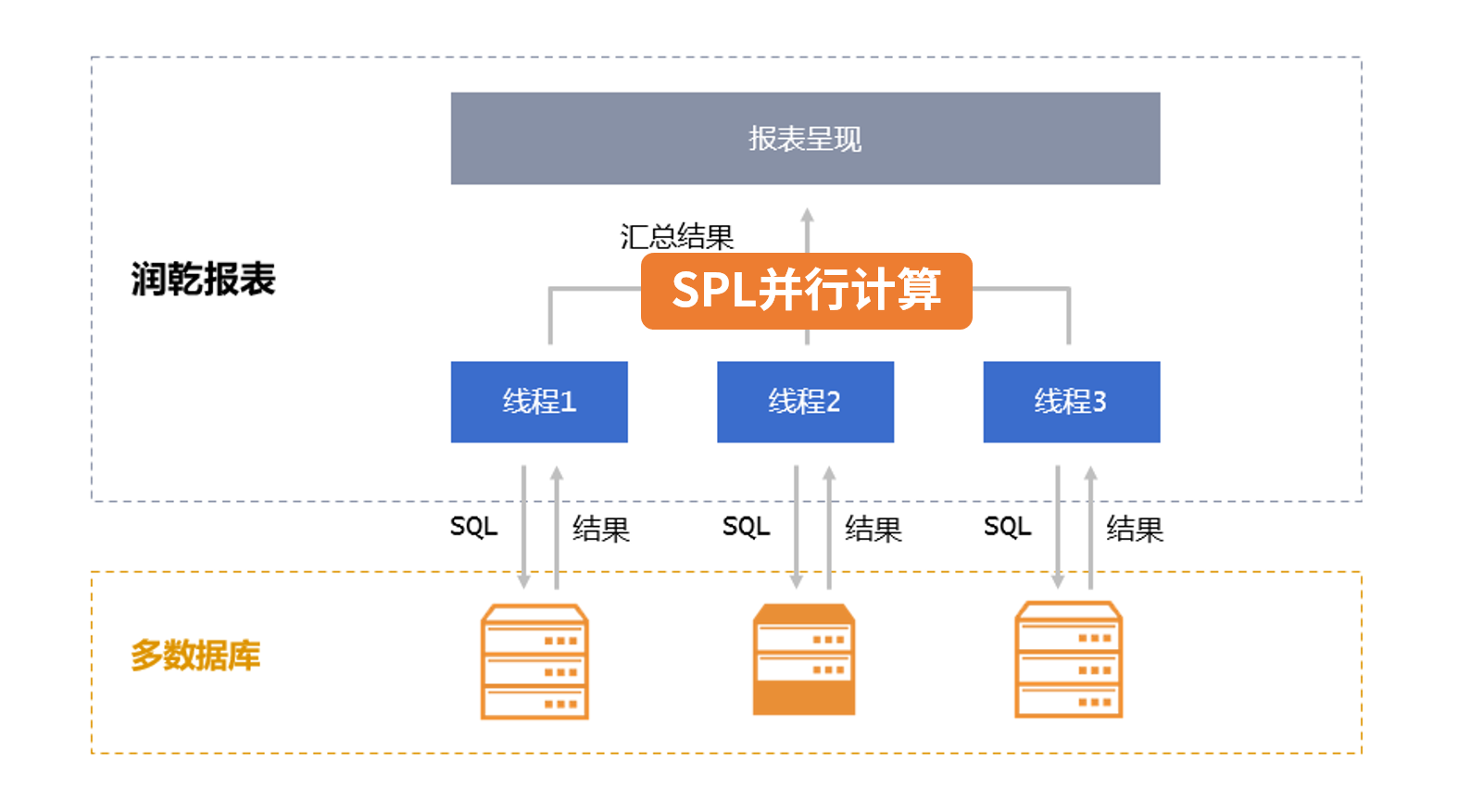
SPL数据准备层要比报表本身的计算范围更广,能力更强,完全可以把原先要在报表中进行的性能低下的运算放到数据准备层中高效计算,这样大数据时代下报表的性能也一并都解决了。
全面工具化持续领先
这些就是报表工具的第二次革命,数据准备阶段的工具化,让做报表从半自动洗衣机变成了全自动洗衣机。简单做的快,低成本应对,就再也不怕报表的没完没了。

报表的两次革命都是由润乾报表主导,也并非偶然,是润乾深耕报表领域多年的结果。
第一次革命,用非线性报表模型,解决了中国式复杂报表的难题,也让国产软件在报表这个领域一直以碾压式的优势走到现在
第二次革命,解决了大数据时代报表数据准备的难题,也让整个报表的解决方案更完整,有了一个质的提升。
除润乾外,其它报表工具厂商也在一定程度地强化数据准备能力,比如支持多异构数据源合并等,但和SPL功能相比还相差巨大,数据计算的难度更大,模仿复杂度要比非线性报表高得多,所以很少有厂商能成功跟随了。
不过,SPL已经开源
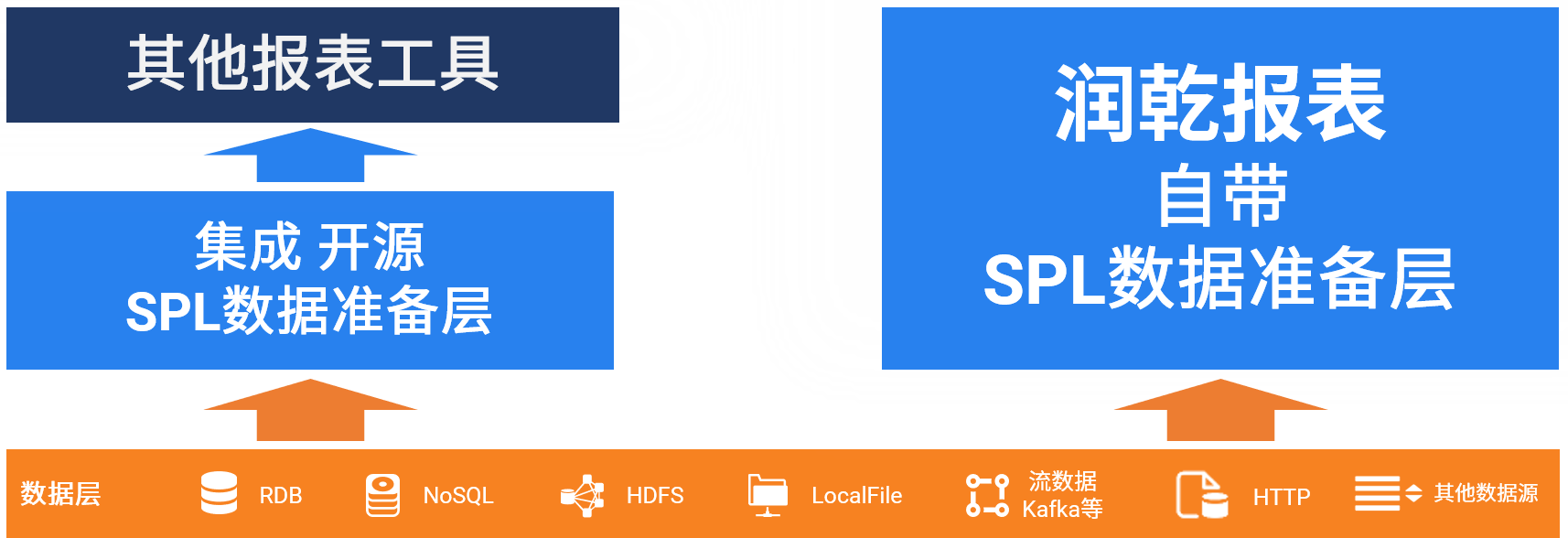
应用开发人员可以用它为任何报表工具提供数据准备服务,集成也很简单,并不需要报表工具厂商配合。当然,润乾这种全内置的机制会更方便,运行效率也更高。
有了这个SPL数据准备工具的加持,又可以让国产报表领先很多年了。