01动态参数查询
动态参数查询适合用IDE实现
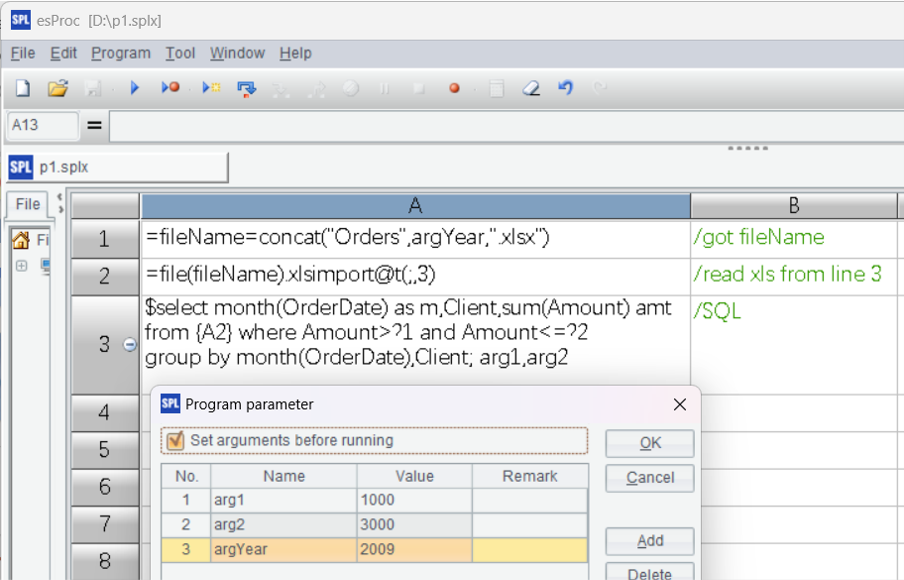
有一批以年份命名的xls,需要用参数动态指定文件名和金额范围,并对文件进行查询
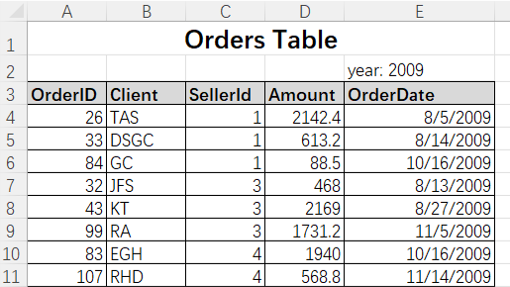
Orders2009.xlsx
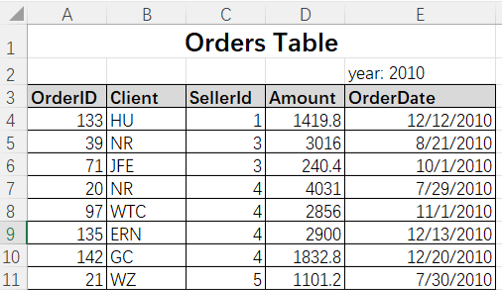
Orders2010.xlsx
代码和参数
执行和调试
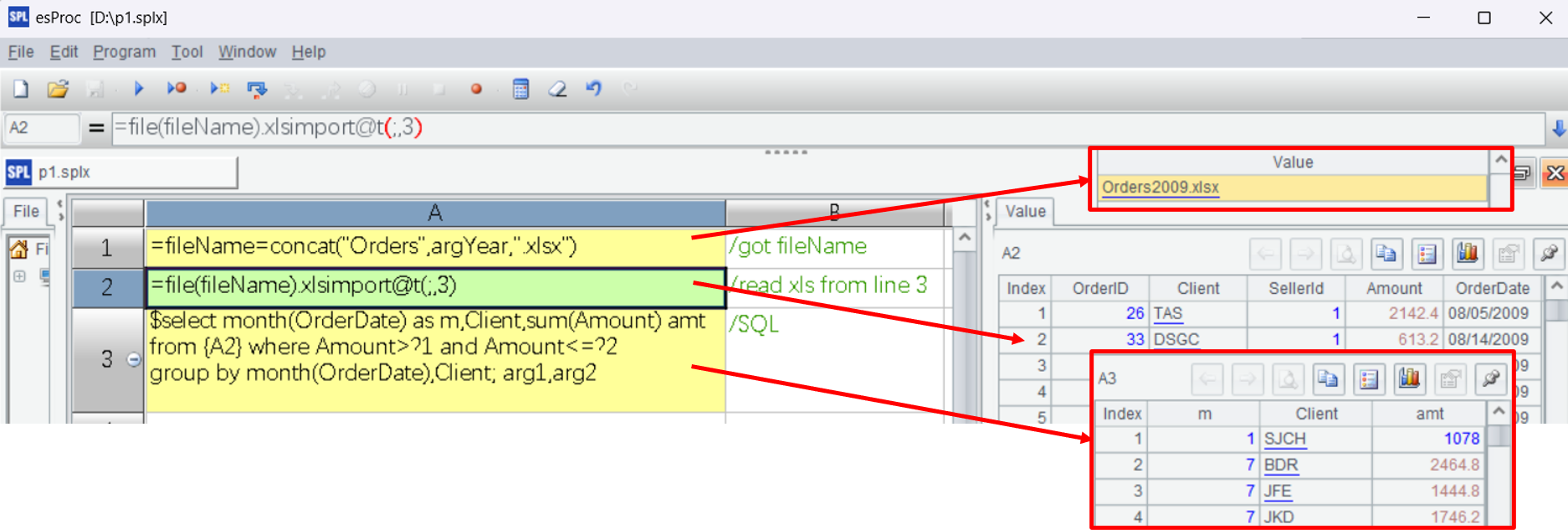
xlsimport@t(;,3)表示从第3行读xls直至结尾,读出后首行做列名
02流程相关计算
流程相关的计算有一定复杂性,适合用IDE
判断两个行数相同的csv(旧文件和修改后的新文件),有多少行的数据是一致的(没有修改过),有多少行不一致(修改过)。
Orders_old.csv

Orders_new.csv
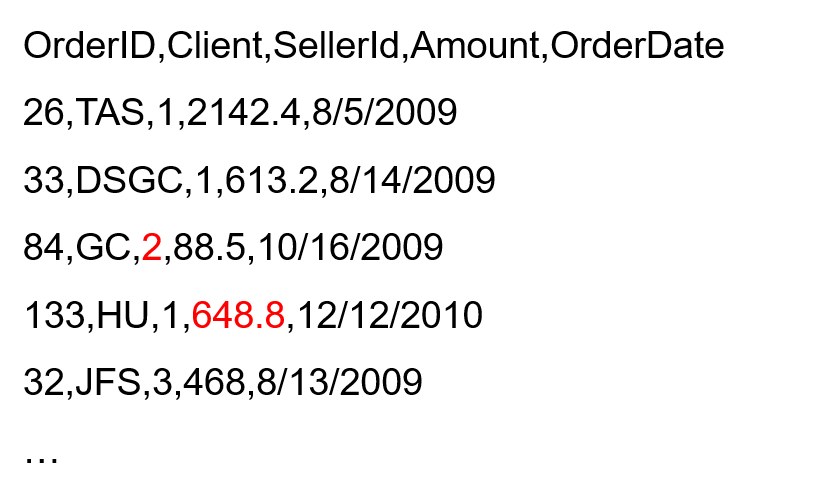
用循环的流程来比较两个文件的同行的记录
| A | B | C | |
| 1 | =old=file("Orders_old.csv").import@ct() | /读旧文件 | |
| 2 | =new=file("Orders_new.csv").import@ct() | /读新文件 | |
| 3 | for old.len() | =cmp(old(A3),new(A3)) | /循环比较两个文件的同行的记录 |
| 4 | =@|B3 | //比较结果追加到B4中 | |
| 5 | =B4.count(~==0) | //一致的行数 | |
| 6 | =B4.count(~!=0) | //不一致的行数 |
- “for n”表示从1循环到n,循环体为缩进的B3-B4
- 循环体内可以引用默认的循环变量,即for所在的单元格A3;也可以引用默认的循环计数#A3
- 单元格名可作为默认变量名,如A3、B4;也可以定义一个有意义的变量名,如old、new
- @代表当前格
更多例子
- 将 2014 年前 10% 的销售员每人再给予 5% 的业绩奖励
- 找出某机构的所有下级和下级的层数
- 根据用户支付数据明细表,统计各个用户 2014 年每月应付金额的汇总表
- 根据文本 1 中的关键词,在文本 2 中查找,输出相关的字符串
- 根据股票收盘价,列出 2020 年 1 月 1 日至 10 日每天的 20 日收盘均价
- 根据销售表,统计出 2014 年每个月达到 20 笔订单所需天数
- 根据员工收入表,求员工在本部门的收入排名
- 根据成绩表,求出一班学生 ID 为 8 的学生的各科成绩在本班的排名
- 根据股票收盘价,计算 2019 年每个交易日的全年累计成交金额
- 根据销售表数据,统计 2014 年第一季度到哪一天完成了销售总额 15 万的季度目标
03复杂运算
复杂运算编写难度较大,适合IDE
某股票指数最长的连续上涨天数。
TDATE,CLOSING,OPENING,HIGHEST,LOWEST,VOLUME 1/2/2020,3085.2,3066.34,3098.1,3066.34,29.25B 1/3/2020,3083.79,3089.02,3093.82,3074.52,26.15B 1/6/2020,3083.41,3070.91,3107.2,3065.31,31.26B 1/7/2020,3104.8,3085.49,3105.45,3084.33,27.66B 1/8/2020,3066.89,3094.24,3094.24,3059.13,29.79B
| A | B | |
| 1 | =T("share_index.csv").sort(TDATE) | /读文件并排序 |
| 2 | =A1.group@i(CLOSING < CLOSING[-1]) | /指数上涨的记录分到同一组 |
| 3 | =A2.max(~.count()) | /取最大值 |
CLOSING[-1]表示上一条指数,CLOSING < CLOSING[-1]这个条件表示指数下跌时,之前指数上涨的记录会被分到同一组(则每条下跌的记录会单独分一组)
某xls保存着考勤数据,需要横向转换成新xls,使每人每天7条变成每人每天2条
| A | B | C | D | E | |
| 1 | Per_Code | in_out | Date | Time | Type |
| 2 | 1110263 | 1 | 2013-10-11 | 09:17:14 | In |
| 3 | 1110263 | 6 | 2013-10-11 | 09:17:14 | Break |
| 4 | 1110263 | 5 | 2013-10-11 | 11:38:21 | Return |
| 5 | 1110263 | 0 | 2013-10-11 | 11:43:21 | NULL |
| 6 | 1110263 | 6 | 2013-10-11 | 13:21:30 | Break |
| 7 | 1110263 | 5 | 2013-10-11 | 14:25:58 | Return |
| 8 | 1110263 | 2 | 2013-10-11 | 18:28:55 | Out |
| A | B | C | D | E | F | |
| 1 | Per_Code | Date | In | Out | Break | Return |
| 2 | 1110263 | 10/11/2013 | 09:17:14 | 18:28:55 | 11:37:00 | 11:38:21 |
| 3 | 1110263 | 10/11/2013 | 09:17:14 | 18:28:55 | 13:21:30 | 14:25:58 |
涉及大量有序计算、分组后计算
| A | B | |
| 1 | =T("attendance.xlsx").sort(Per_Code,Date,Time) | /取数据并按人员、日期、时间排序 |
| 2 | =A1.group@o((#-1)\7) | /每7条记录(按人员)分一组 |
| 3 | =A2.(~([1,7,2,3,1,7,5,6])) | /对每个组,取出当天的有序数据 |
| 4 | =A3.conj( [~.Per_Code,~.Date] |~.(Time).m([1,2,3,4]) |[~.Per_Code,~.Date] |~.(Time).m([5,6,7,8])) | /将组内数据整理成序列,并合并各组 |
| 5 | =create(Per_Code,Date,In,Out,Break,Return) | /创建空结果集 |
| 6 | >A5.record(A4) | /向结果集填入数据 |
| 7 | =file("result.xlsx").xlsexport@t(A5) | /输出成新xls |
- group@o表示分组时不必事先排序
- 函数m可按序号或数组访问集合成员(包括记录)
更多例子
- 统计某几个重点州的平均工资,其他地区的员工另分一组统计
- 某支股票在2019年最后10个交易日收盘价较前日的涨幅
- 哪几届奥运会的中国奖牌榜比俄罗斯靠前
- 计算两大股票指数在某一时间段内的每日相对收益率
- 统计时间区间内某支股票收盘价最高的当天,相对前日的涨幅
- 统计时间区间内某股票收盘价涨幅超过3%的交易日,相对前日的交易量涨幅
- 划分几个薪资区间段,统计各段的员工总数、平均工资
- 按选课表的顺序,查找哪些课程不在选课表中(无人选)
- 根据用户的支付明细,统计各用户2014年每月的应付金额
04解析复杂格式的文本
解析格式复杂的文本需要较多步骤,适合IDE。
txt含有多个邮件,每个邮件相当于4字段的记录,且Content字段行数不定,需要按Receiver和Date区间查询记录
Sender: Melody<Melody@bus.emory.edu> Receiver: Susan<Susan@google.com> Date: 1/14/2020 Content: Do you yahoo!? SBC Yahoo!DSL - Dow only @29.95per month! Sender: Tom<Tom@163.com> Receiver: rose<rose@163.com> Date: 2/24/2020 Content: IMPORTANT NOTICE: The information in this email(and any attachments) is confidential. If you are not the intended recipient, you must not use or disseminate the …

查询记录不难,难在解析不定行记录
| A | B | |
| 1 | =file("mail.txt").import@si() | /将文件读为行的集合 |
| 2 | =A1.select(~!="") | /去除空行 |
| 3 | =A2.group@i(~=="Sender:") | /以"Sender:"为标记将集合分组,每组是一条不定行的记录 |
| 4 | =A3.new(~(2):Sender,~(4):Receiver,date(~(6)):Date ,~.to(8,).concat():Content) | /将不定行记录整理成规范记录 |
| 5 | =A4.select(like@c(Receiver,"*"+arg_name+*") && Date>arg_begin && Date<=arg_end ) | /查询 |
- group@i表示如果条件为真,则结束之前的分组,并开始新分一组
- ~是集合的当前成员,在A3中表示当前行,在A4中表示当前组,对应一条不定行的记录
- A4中的~(2)取当前组中的第2行;~.to(8,)取第8行直到当前组的末尾
更多例子
- 用正则表达式将不定行记录解析为规范文本
- 将交叉表形式的文本解析成规范文本(逆转置)
- csv的字段需要用成对的引号来配对,而不是简单用逗号拆分
- csv某字段包含子字段,且是用分节串来描述
- csv某字段的子字段是分节串,其中第一节为Name时不含节值
- 当Type字段为1时Version没有子字段,否则Version有子字段
- 遍历某目录下所有的文件,查找并替换指定的字符串
- 去掉txt中重复出现的段落,并保持原段落的顺序
- txt的字符串字段前后有空白
- 某字段按分隔符拆分成N行后是规范二维表
05解析/生成复杂格式的xls
Xls有一些独特的复杂格式,适合用IDE解析。
文件的单元格有类似key=value格式的数据,也有些空白格,需要输入key并查询对应的所有value
| A | B | C | D | E | |
| 1 | No=123 | ver=456 | Cos=789 | ||
| 2 | No=678 | ver=783 | No=900 | U=89 | |
| 3 | No=330 | Y=67 | ver=890 | Cos=311 | F=19 |
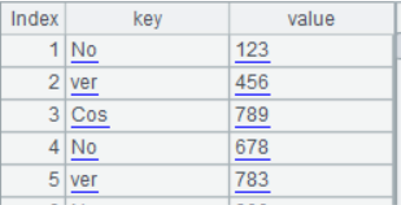
每个单元格对应一条记录,需要整理成规范数据
| A | B | |
| 1 | =file("keyvalue.xlsx").xlsimport@w() | /行内的单元格组成小集合,多个小集合组成大集合 |
| 2 | =A1.conj() | /将两层集合合并为单层集合 |
| 3 | =A2.select(~) | /去掉空白格 |
| 4 | =A3.(~.split("=")) | /按=将每个单元格单元格拆分成2部分 |
| 5 | =A4.new(~(1):key,~(2):value) | /规范化记录,第1部分命名为key字段,第2部分命名为value字段 |
| 6 | =A5.select(key==arg_key) | /查询 |
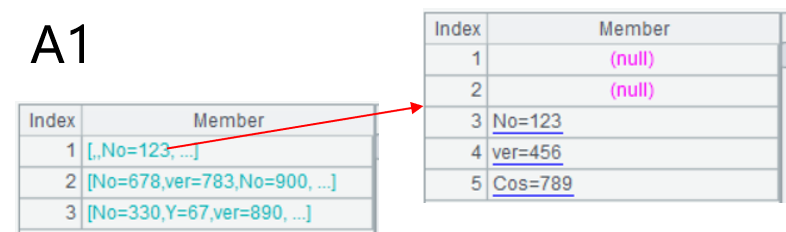
xlsimport@w可将xls解析为集合的集合
复杂的Xls生成难度较大,适合用IDE实现。
上级发来的xls模板由蓝色的表头和白色的空白格组成,下级需要在白色单元格填充数据,填完之后形如:
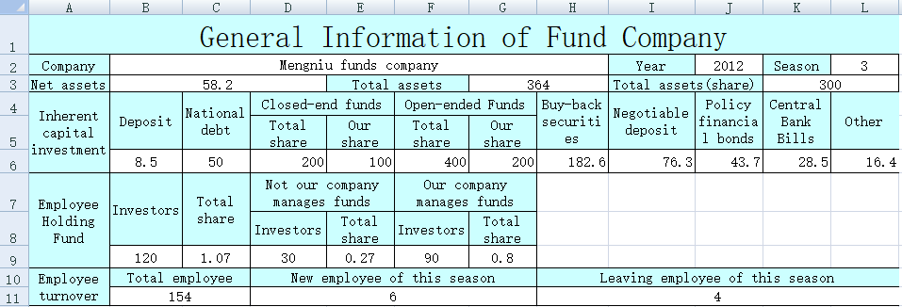
在不规则单元格填数据,常规方式(如POI)代码量巨大
| A | B | C | D | E | F | |
| 1 | Mengniu Funds | 2017 | 3 | 58.2 | 364 | 300 |
| 2 | 8.5 | 50 | 200 | 100 | 400 | 200 |
| 3 | 182.6 | 76.3 | 43.7 | 28.5 | 16.4 | |
| 4 | 120 | 1.07 | 30 | 0.27 | 90 | 0.8 |
| 5 | 154 | 6 | 4 | |||
| 6 | =file("e:/result.xlsx") | =A6.xlsopen() | ||||
| 7 | =C6.xlscell("B2",1;A1) | =C6.xlscell("J2",1;B1) | =C6.xlscell("L2",1;C1) | |||
| 8 | =C6.xlscell("B3",1;D1) | =C6.xlscell("G3",1;E1) | =C6.xlscell("K3",1;F1) | |||
| 9 | =C6.xlscell("B6",1;[A2:F2].concat("\t")) | =C6.xlscell("H6",1;[A3:E3].concat("\t")) | ||||
| 10 | =C6.xlscell("B9",1;[A4:F4].concat("\t")) | =C6.xlscell("B11",1;[A5:C5].concat("\t")) | ||||
| 11 | =A6.xlswrite(B6) | |||||
- A1-F5是待填的数据,A7-F10为填写过程
- 第6、9、11行有连续单元格,SPL可以简化代码一次性填入
更多例子
- 个别行的第2列缺失,这些行的其他列需要后移一位
- 跳过xls的部分无效列
- 读取自由格式的xls
- 读取交叉表格式的xls
- 读取主子表格式的xls
- 根据世界各国的经济指标统计xls文件,求中美两国差距较大的经济指标对比
- 将一个sheet里的多个卡片式表格,整理成规范二维表
- 将多个卡片式sheet合并成规范二维表,每个卡片对应一行
- 将某列按分隔符拆分成N行后是规范二维表
- 将文件按固定行数拆分成多个sheet或文件
- 将某一固定列和其他各列组合,每个组合分别写入sheet或文件
- 将一个行式文件拆分成多个卡片式sheet,每个卡片对应一行
06多种数据源
IDE支持多种数据源,除了csv\txt\xls\xlst,还包括数据库\json\xml\http\SalesForce等几十种数据源,还可以进行跨源计算。
从http取数据,和csv进行关联计算,并分组汇总
| A | B | |
| 1 | =Orders=json(httpfile("http://127.0.0.1:6868/api/orders").read()) | /从http取数据 |
| 2 | =Employees=T("d:/Emp.csv") | /从csv取数据 |
| 3 | =join@1(Orders:o,SellerId;Employees:e,EId) | /关联 |
| 4 | =A3.group(e.Detp,o:dept.Client:client;sum(Amount):amt,count(1):cnt) | /分组汇总 |