esProc SPL倍增Java程序员开发效率

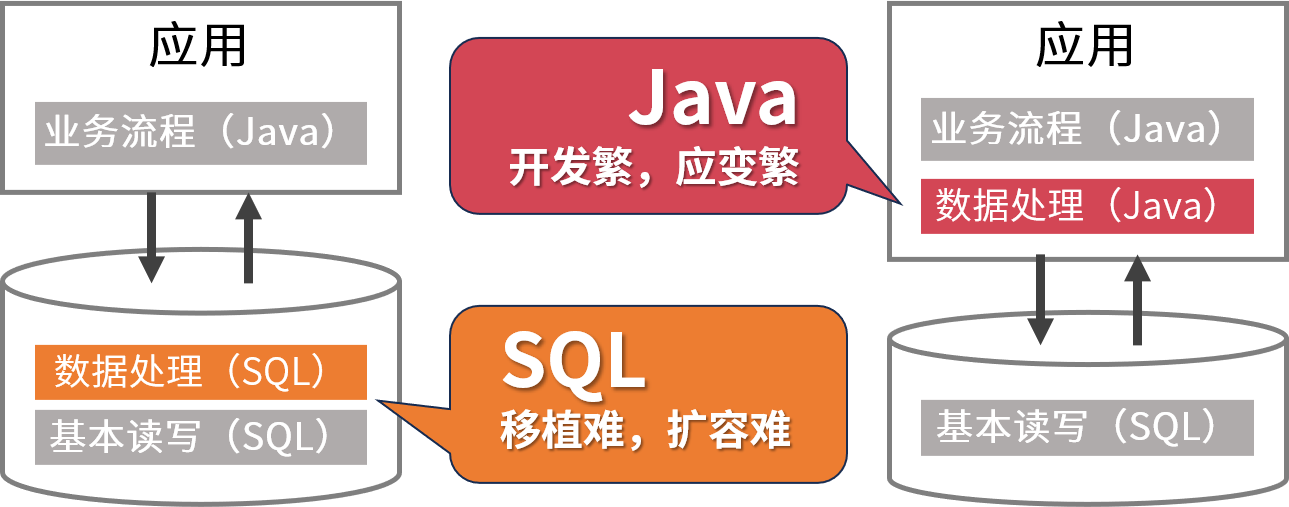
Java程序员的困境
数据处理逻辑用Java?还是用SQL?
来看看Java有多繁琐
例两个字段的分组聚合
JAVA
Map < Integer, Map < String, Double > > summary = new HashMap<>();
for (Order order : orders) {
int year = order.orderDate.getYear();
String sellerId = order.sellerId;
double amount = order.amount;
Map < String, Double> salesMap = summary.get(year);
if (salesMap == null) {
salesMap = new HashMap<>();
summary.put(year, salesMap);
}
Double totalAmount = salesMap.get(sellerId);
if (totalAmount == null) {
totalAmount = 0.0;
}
salesMap.put(sellerId, totalAmount + amount);
}
for (Map.Entry < Integer, Map < String, Double > > entry : summary.entrySet()) {
int year = entry.getKey();
Map < String, Double> salesMap = entry.getValue();
System.out.println("Year: " + year);
for (Map.Entry < String, Double> salesEntry : salesMap.entrySet()) {
String sellerId = salesEntry.getKey();
double totalAmount = salesEntry.getValue();
System.out.println(" Seller ID: " + sellerId + ", Total Amount: " + totalAmount);
}
}
SQL只要一句
SELECT year(orderdate),sellerid,sum(amount) FROM orders GROUP BY year(orderDate),sellerid
Stream、Kotlin、Scala改进也很有限
Stream
Map < Integer, Map < String, Double > > summary = orders.stream()
.collect(Collectors.groupingBy(
order -> order.orderDate.getYear(),
Collectors.groupingBy(
order -> order.sellerId,
Collectors.summingDouble(order -> order.amount)
)
));
summary.forEach((year, salesMap) -> {
System.out.println("Year: " + year);
salesMap.forEach((sellerId, totalAmount) -> {
System.out.println(" Seller ID: " + sellerId + ", Total Amount: " + totalAmount);
});
});
Kotlin
val summary = orders
.groupBy { it.orderDate.year }
.mapValues { yearGroup ->
yearGroup.value
.groupBy { it.sellerId }
.mapValues { sellerGroup ->
sellerGroup.value.sumOf { it.amount }
}
}
summary.forEach { (year, salesMap) ->
println("Year: $year")
salesMap.forEach { (sellerId, totalAmount) ->
println(" Seller ID: $sellerId, Total Amount: $totalAmount")
}
}
Scala
val summary = orders
.groupBy(order => order.orderDate.getYear)
.mapValues(yearGroup =>
yearGroup
.groupBy(_.sellerId)
.mapValues(sellerGroup => sellerGroup.map(_.amount).sum)
)
summary.foreach { case (year, salesMap) =>
println(s"Year: $year")
salesMap.foreach { case (sellerId, totalAmount) =>
println(s" Seller ID: $sellerId, Total Amount: $totalAmount")
}
}
编译语言不能热切换

难以应对多变业务
esProc SPL令Java程序员摆脱困境!
代码简洁远超Java,堪比SQL
例两个字段的分组聚合
| SPL | Orders.groups(year(orderdate),sellerid;sum(amount)) |
| SQL | SELECT year(orderdate),sellerid,sum(amount) FROM orders GROUP BY year(orderDate),sellerid |
其实比SQL更简单
例计算股票连涨天数
SQL
SELECT MAX(ContinuousDays) FROM (SELECT COUNT(*) ContinuousDays FROM (SELECT SUM(UpDownTag) OVER ( ORDER BY TradeDate) NoRisingDays FROM (SELECT TradeDate, CASE WHEN price>LAG(price) OVER ( ORDER BY TradeDate) THEN 0 ELSE 1 END UpDownTag FROM Stock ) ) GROUP BY NoRisingDays )
SPL
| A | |
| 1 | =Stock.sort(tradeDate).group@i(price < price[-1]).max(~.len()) |
纯Java开发,无缝嵌入Java框架,享受架构优势,再也不纠结
JAR包嵌入使用
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
st =con.prepareCall("call SplScript(?)");
st.setObject(1, "A");
st.execute();
ResultSet rs = st.getResultSet();
ResultSetMetaData rsmd = rs.getMetaData();
标准JDBC执行/调用SPL脚本
与Java框架配合

解释执行,天然热切换

丰富数据源支持,计算不依赖于数据库,没有数据库和多个数据库时也能用

