可能是对Excel数据分析师最友好的编程

1网格代码直观自然、调试便利
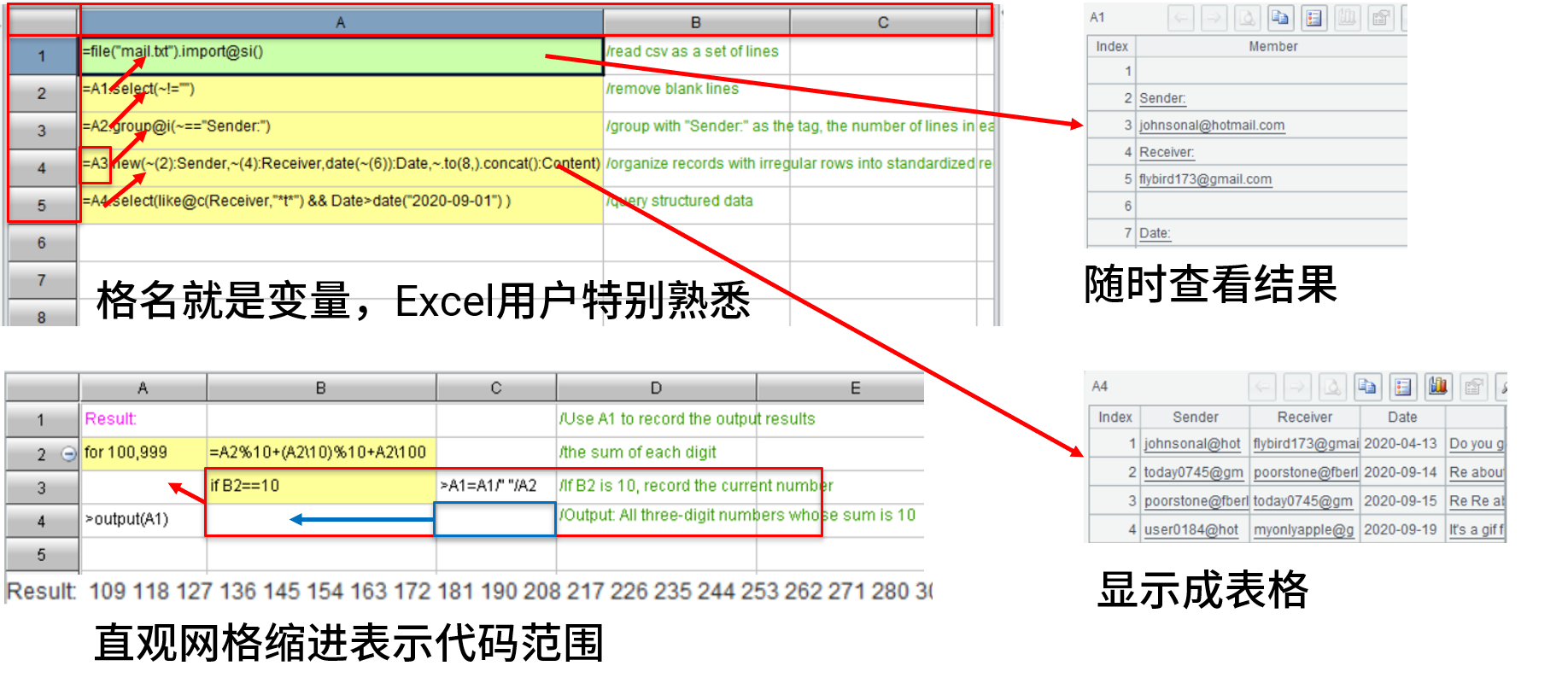
从此告别烦人的print大法
2强大数据运算能力
计算每支股票最长连涨天数
| A | |
| 1 | =T("stock.xlsx") |
| 2 | =A1.sort(DT) |
| 3 | =A2.group(CODE;~.group@i(CL< CL[-1]).max(~.len()):max_increase_days) |
只要三行
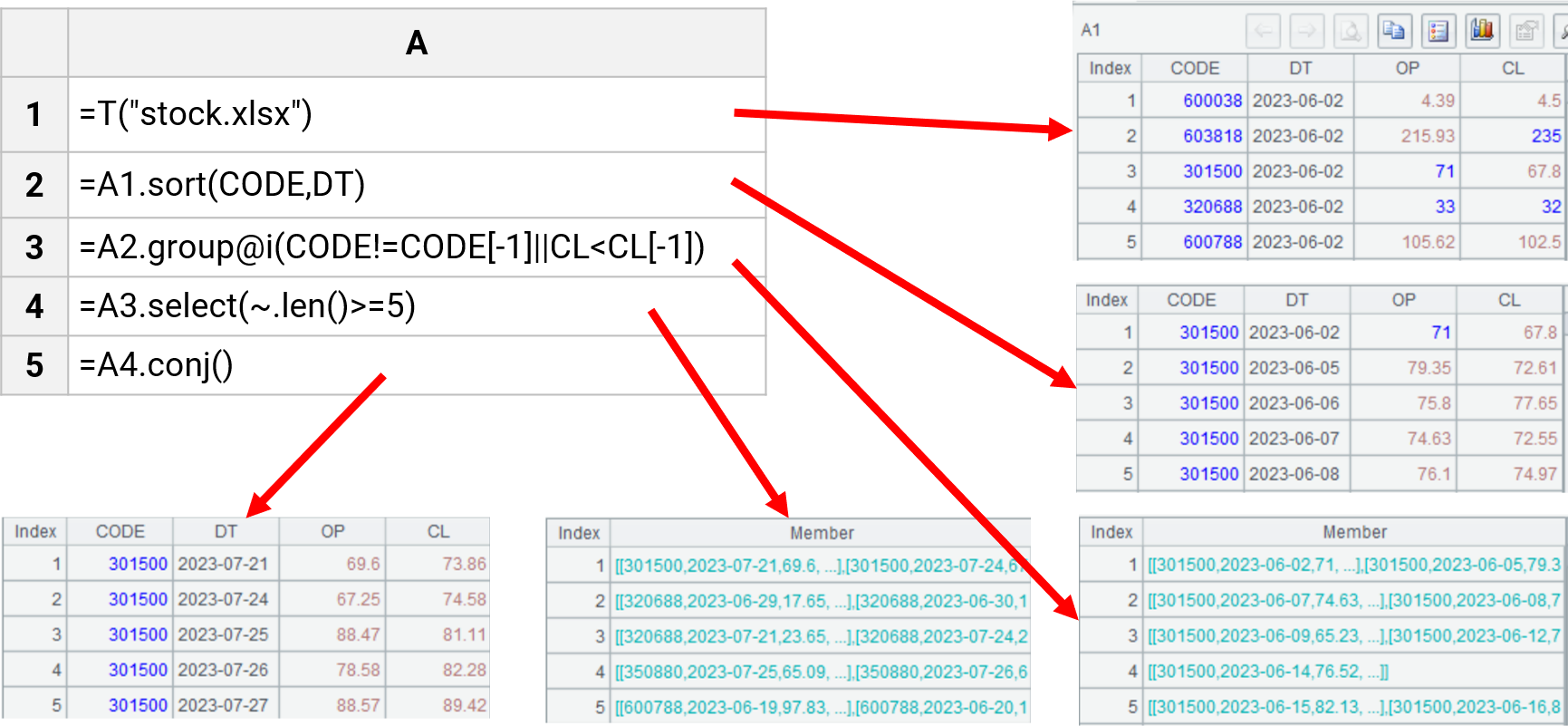
找出股票连涨超过5天的区间
| A | |
| 1 | =T("stock.xlsx") |
| 2 | =A1.sort(CODE,DT) |
| 3 | =A2.group@i(CODE!=CODE[-1]||CL< CL[-1]) |
| 4 | =A3.select(~.len()>=5) |
| 5 | =A4.conj() |
解决Excel难题
内置游标技术支持大数据
计算每支股票最长连涨天数
| A | |
| 1 | StockRecords.txt |
| 2 | =file(A1).cursor@t().sortx(CODE,DT) |
| 3 | =A2.group(CODE;~.group@i(CL< CL[-1]).max(~.len()):max_increase_days) |
找出股票连涨超过5天的区间
| A | |
| 1 | StockRecords.txt |
| 2 | =file(A1).cursor@t().sortx(CODE,DT) |
| 3 | =A2.group(CODE).conj(~.group@i(CL< CL[-1])) |
| 4 | =A3.select(~.len()>=5).conj() |
3强交互性,所见即所得
找出股票连涨超过5天的区间
还有XLL强化Excel
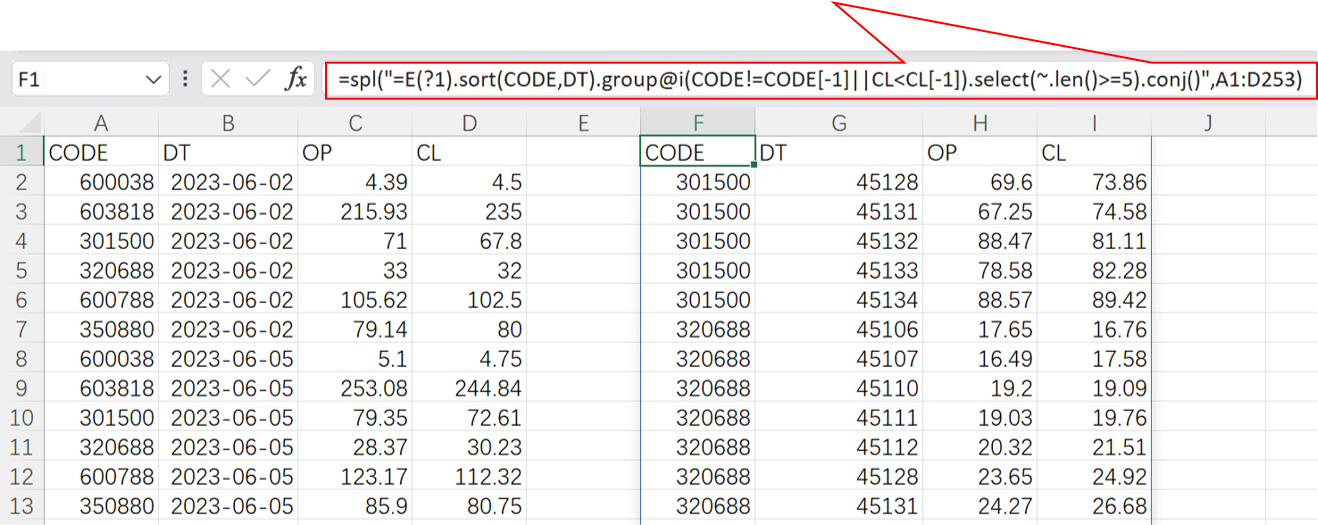
直接在Excel中找出股票连涨超过5天的区间
=spl("=E(?1).sort(CODE,DT).group@i(CODE!=CODE[-1]||CL< CL[-1]).select(~.len()>=5).conj()",A1:D253)