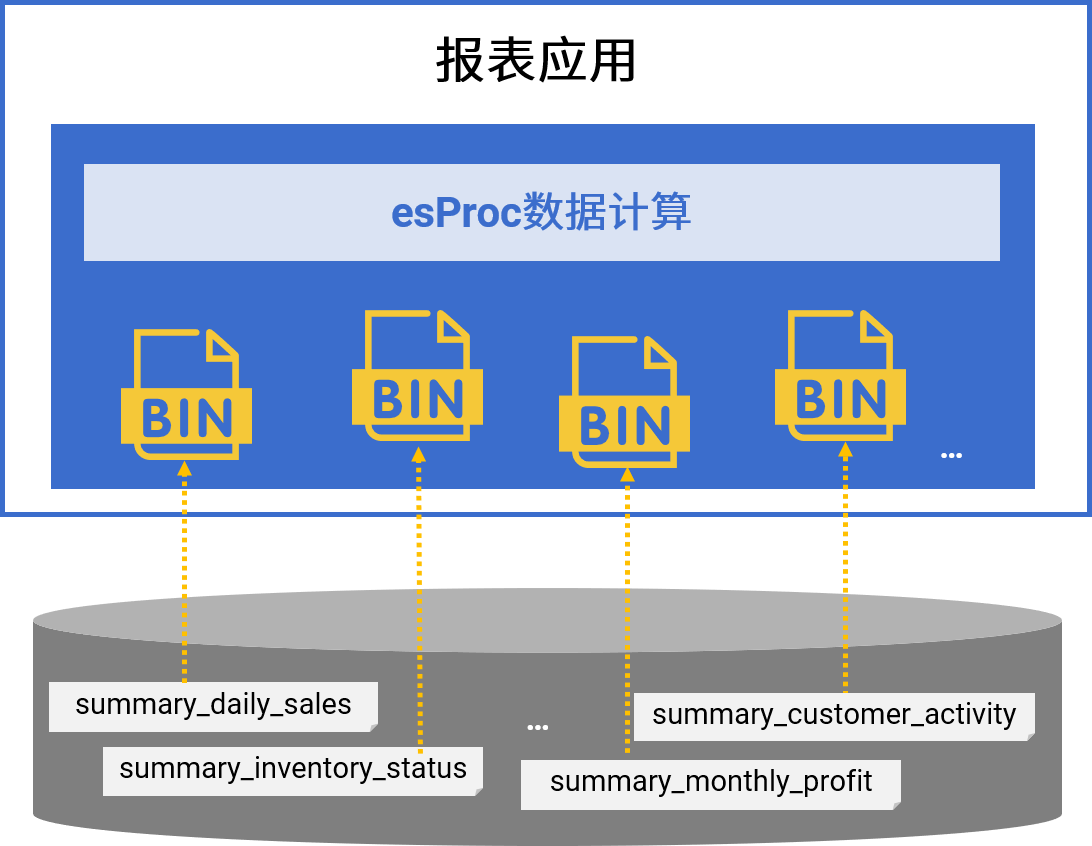
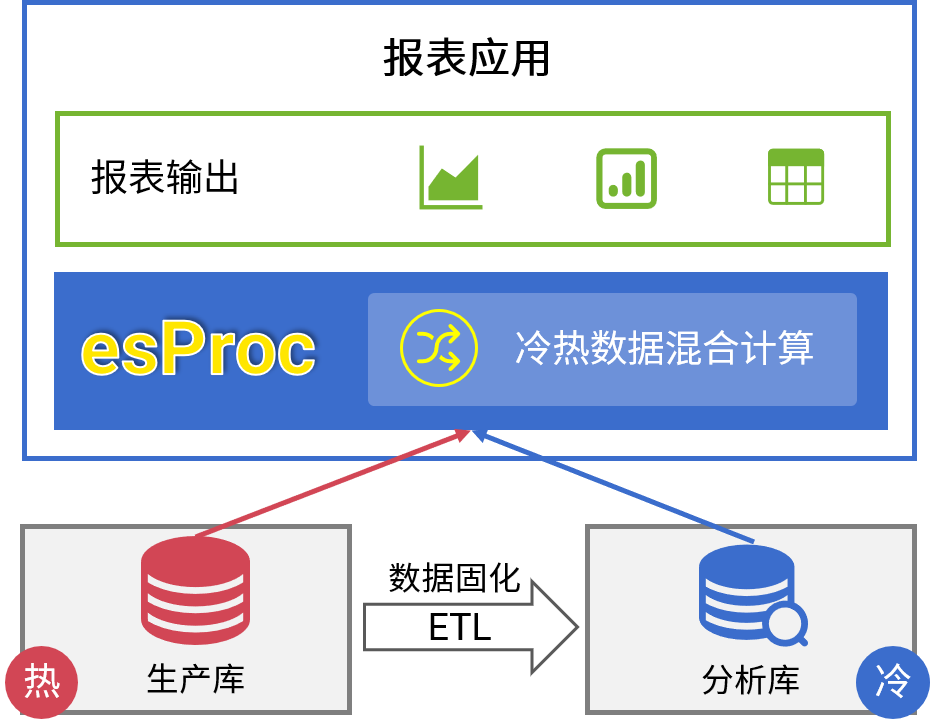
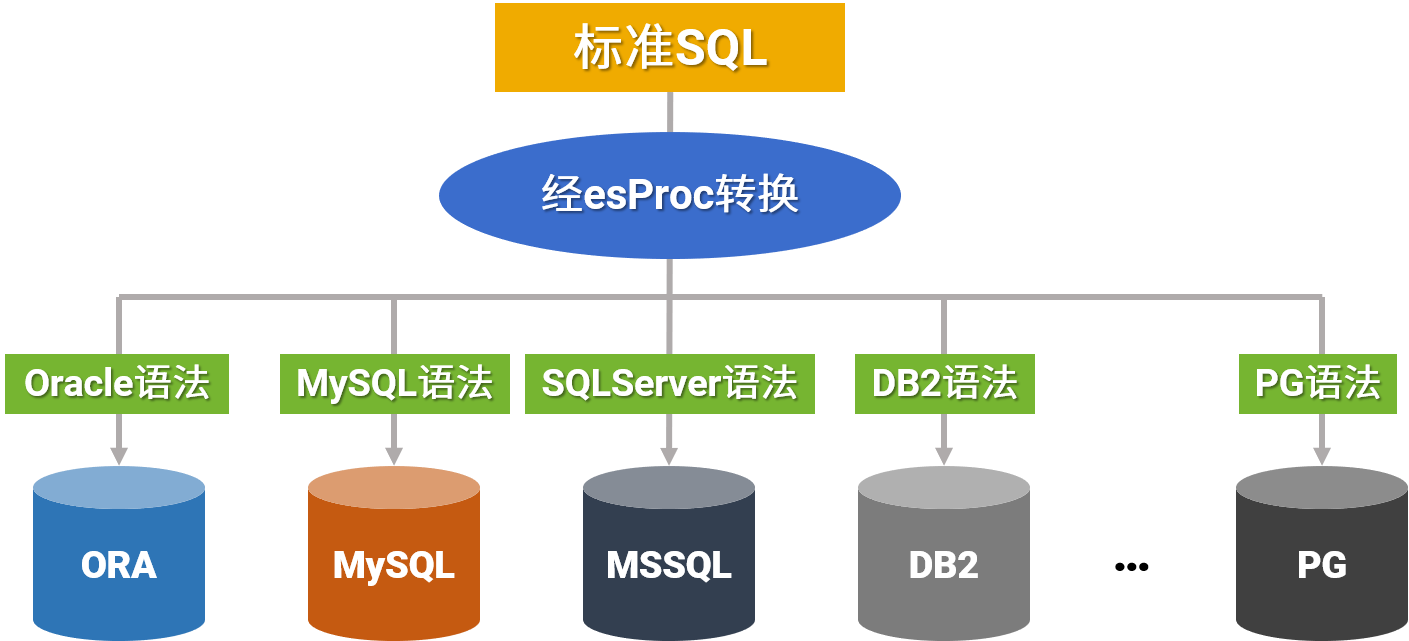
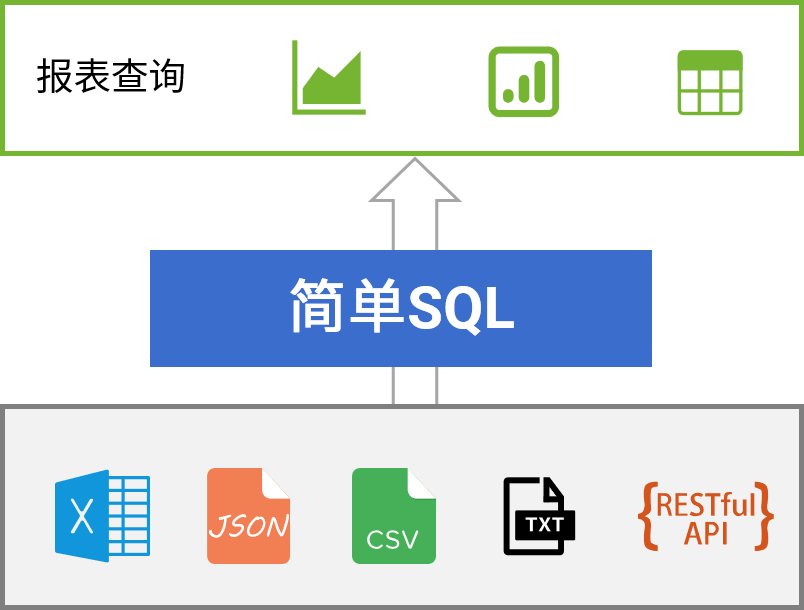
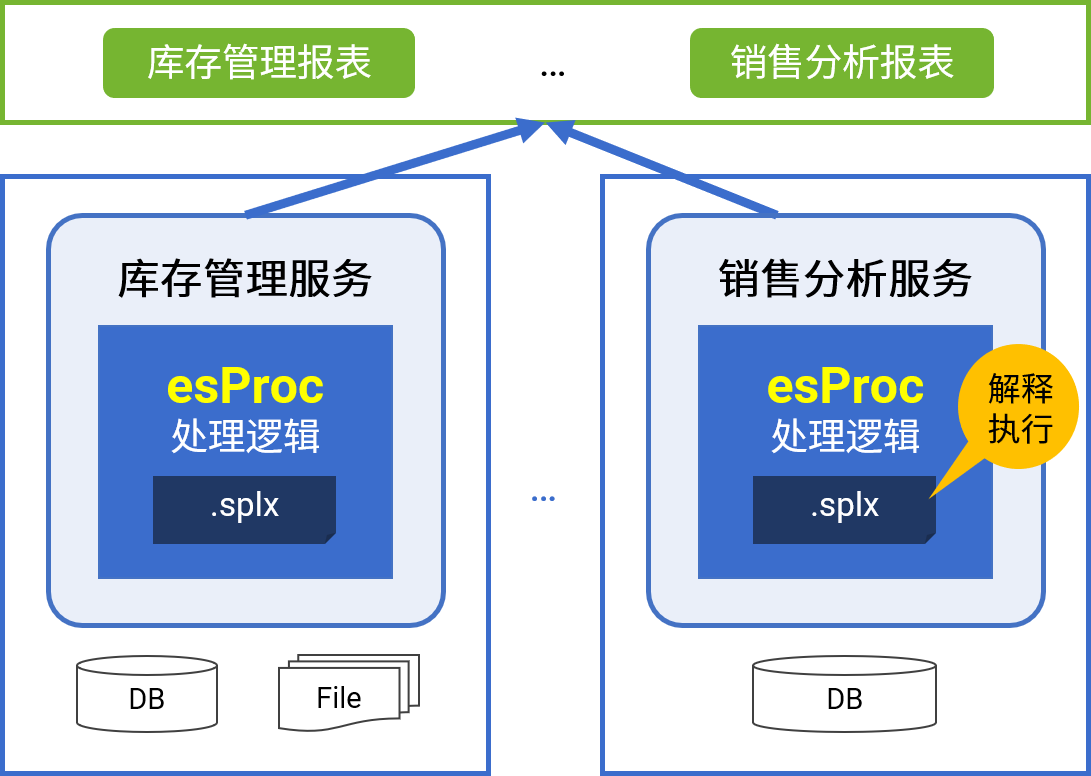
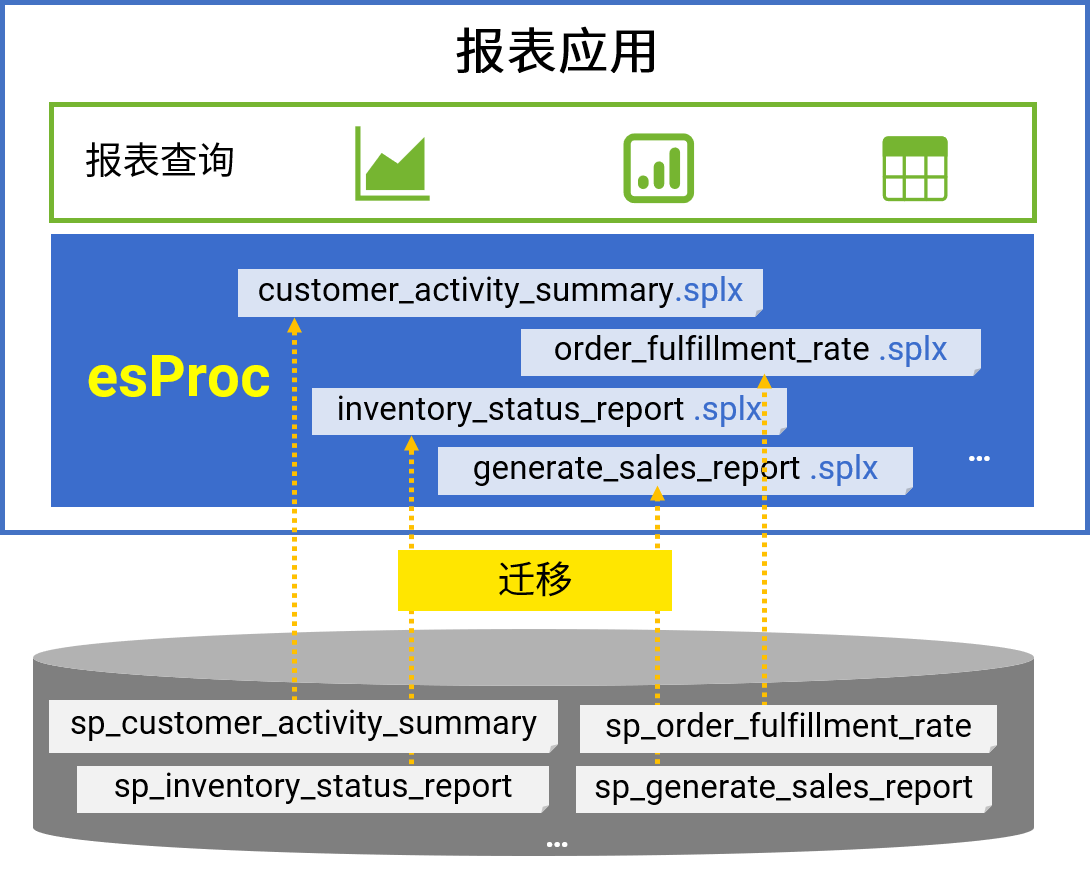
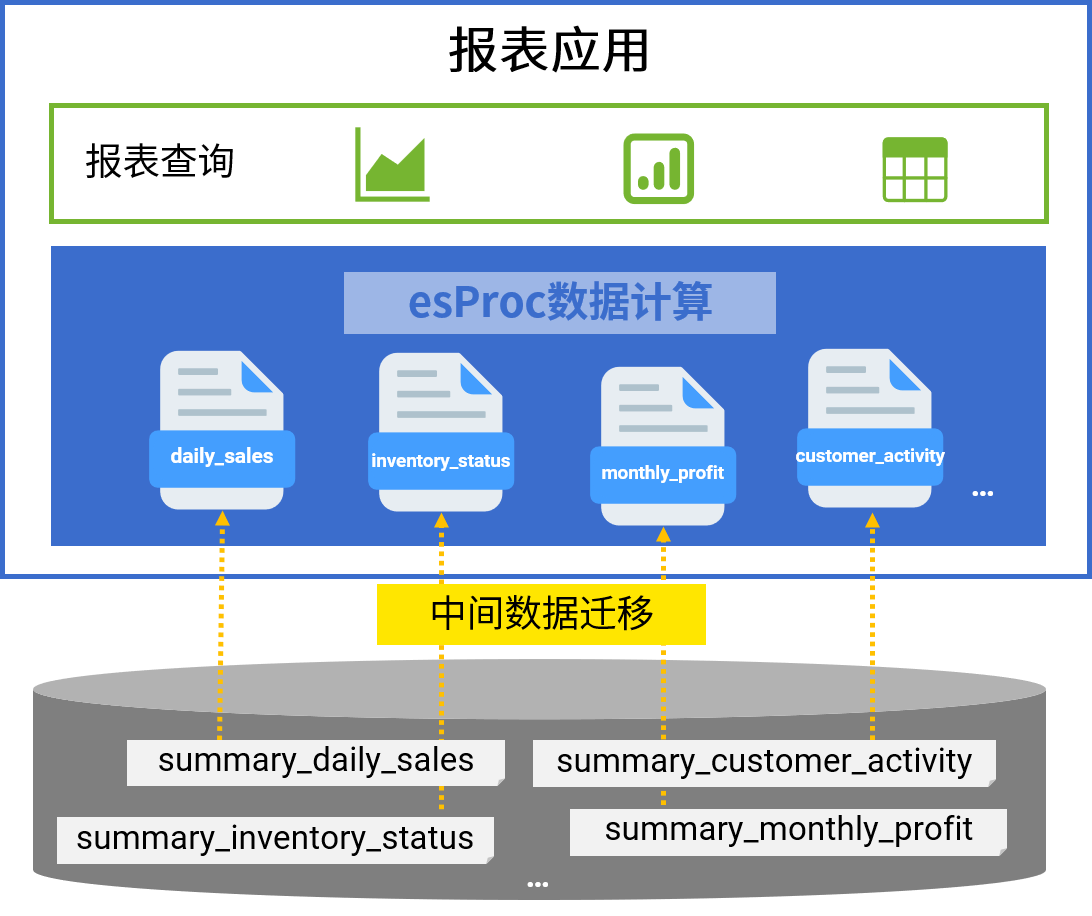
应对没完没了的报表开发
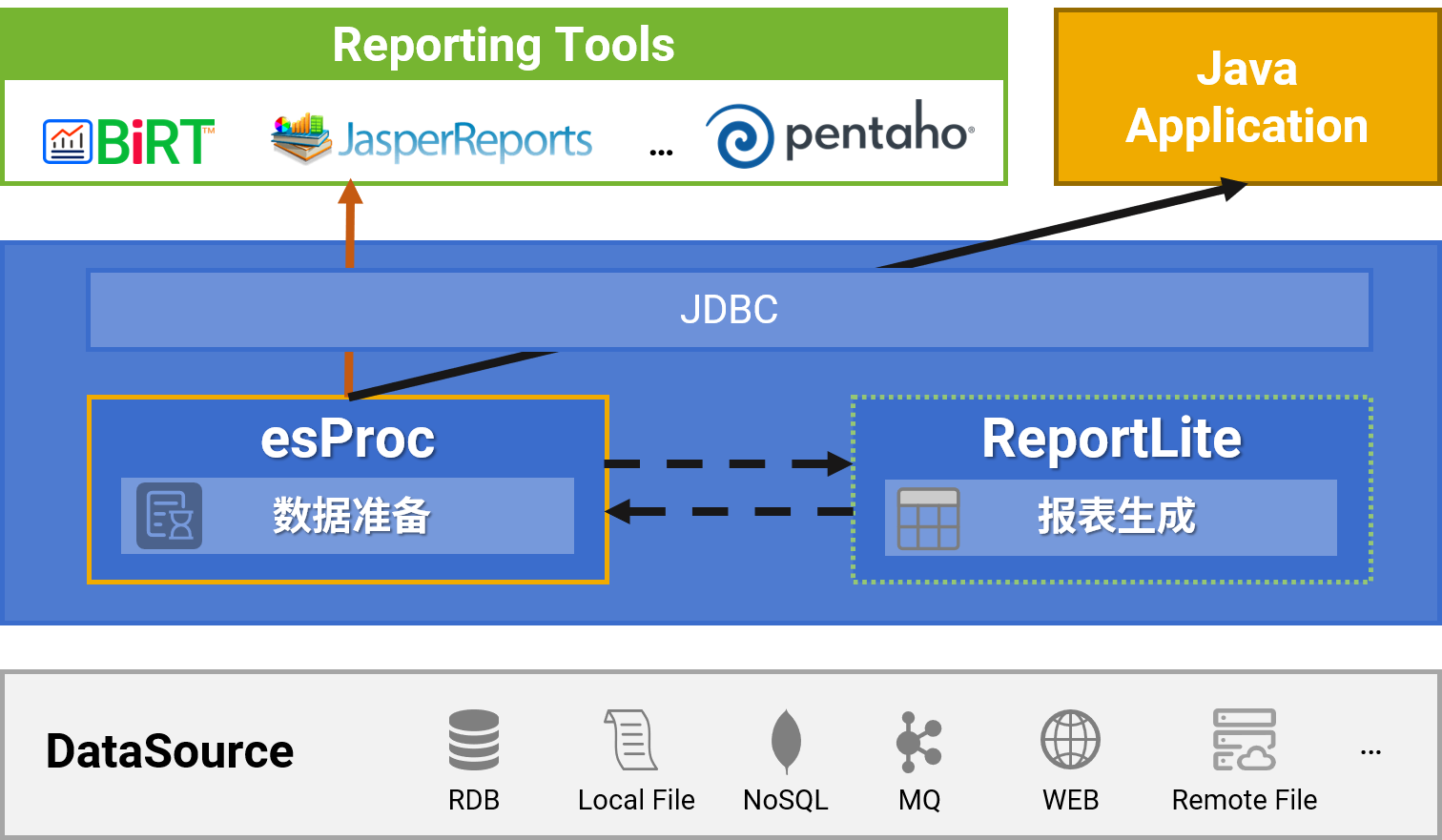
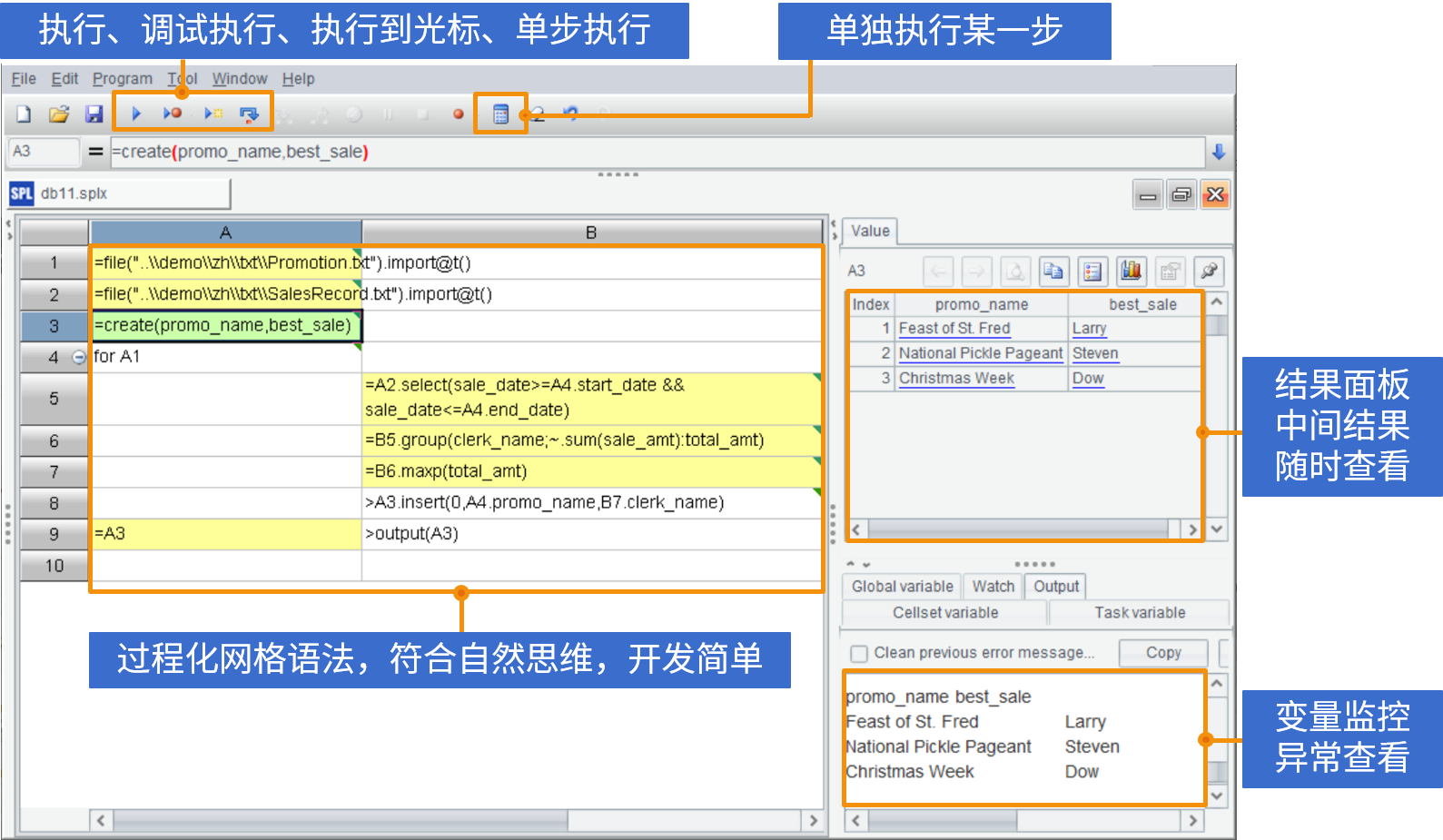
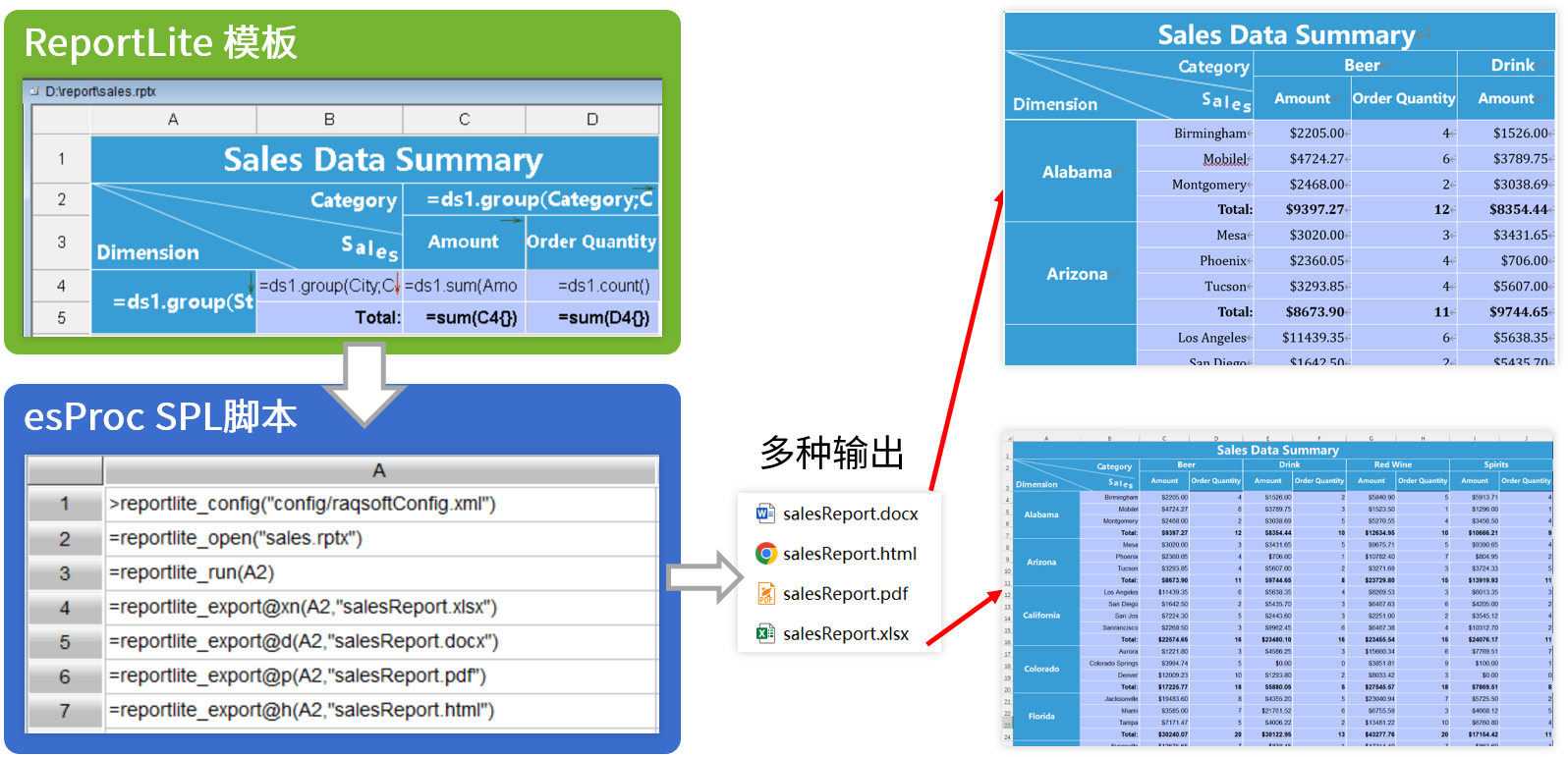
esProc for Reporting
简单开发 · 丰富格式 · 多样源 · 轻量级 · 高性能

SELECT CUSTOMER, AMOUNT, SUM_AMOUNT FROM (SELECT CUSTOMER, AMOUNT, SUM(AMOUNT) OVER(ORDER BY AMOUNT DESC) SUM_AMOUNT FROM (SELECT CUSTOMER, SUM(AMOUNT) AMOUNT FROM ORDERS GROUP BY CUSTOMER)) WHERE 2 * SUM_AMOUNT < (SELECT SUM(AMOUNT) TOTAL FROM ORDERS)
| A | B | |
| 1 | =db.query("select customer,amount from orders order by amount desc") | |
| 2 | =A1.sum(amount)/2 | =0 |
| 3 | =A1.pselect((B1+=amount)>=A2) | return A1.to(A3) |
WITH first_login AS (
SELECT userid, MIN(TRUNC(ts)) AS first_login_date FROM login_data GROUP BY userid),
next_day_login AS (
SELECT DISTINCT(fl.userid), fl.first_login_date, TRUNC(ld.ts) AS next_day_login_date
FROM first_login fl LEFT JOIN login_data ld ON fl.userid = ld.userid WHERE TRUNC(ld.ts) = fl.first_login_date + 1),
day_new_users AS (
SELECT first_login_date,COUNT(*) AS new_user_num FROM first_login GROUP BY first_login_date),
next_new_users AS (
SELECT next_day_login_date, COUNT(*) AS next_user_num FROM next_day_login GROUP BY next_day_login_date),
all_date AS (
SELECT DISTINCT(TRUNC(ts)) AS login_date FROM login_data)
SELECT all_date.login_date+1 AS dt,dn. new_user_num,nn. next_user_num,
(CASE WHEN nn. next_day_login_date IS NULL THEN 0 ELSE nn.next_user_num END)/dn.new_user_num AS ret_rate
FROM all_date JOIN day_new_users dn ON all_date.login_date=dn.first_login_date
LEFT JOIN next_new_users nn ON dn.first_login_date+1=nn. next_day_login_date
ORDER BY all_date.login_date;
| A | |
| 1 | =file(“login_data.csv”).import@tc() |
| 2 | =A1.group(userid;fst=date(ts):fst_login,~.(date(ts)).pos(fst+1)>0:w_sec_login) |
| 3 | =A2.groups(fst_login+1:dt;count(w_sec_login)/count(1):ret_rate) |





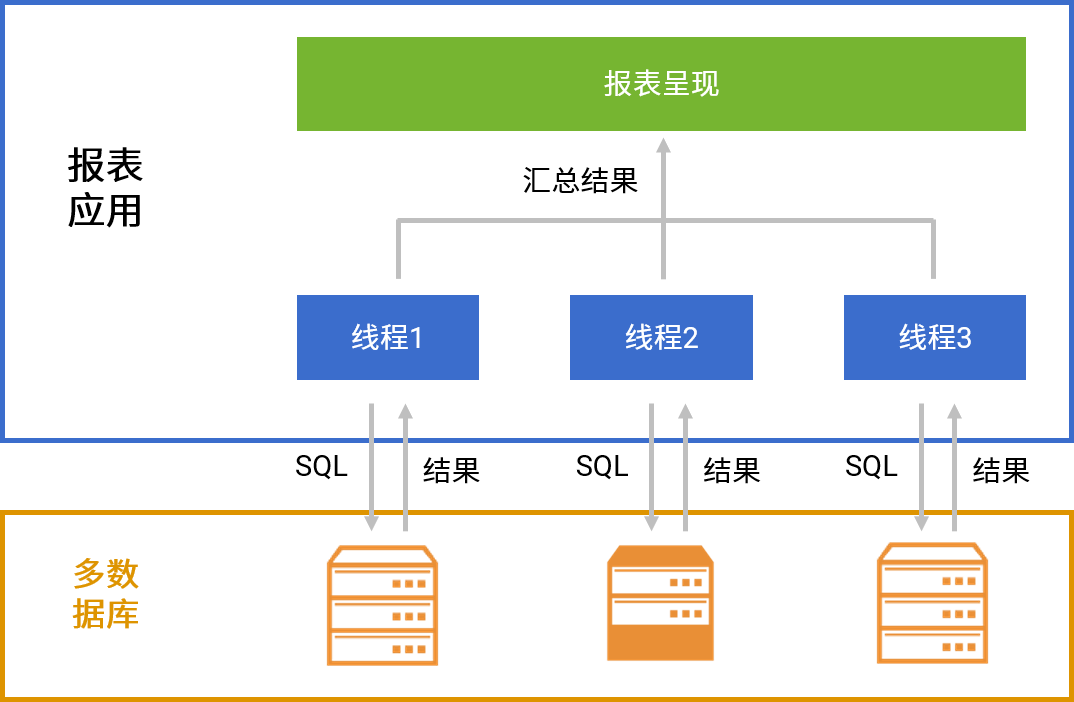
| A | B | |
| 1 | fork to(12) | =connect("oracle") |
| 2 | =B1.query@x("SELECT * FROM CUSTOMER WHERE MOD(C_CUSTKEY,?)=?", n, A1-1) | |
| 3 | =A1.conj() |
| A | B | |
| 1 | SELECT * FROM SUPPLIER | |
| 2 | SELECT * FROM PART | |
| 3 | SELECT * FROM CUSTOMER | |
| 4 | SELECT * FROM PARTSUPP | |
| 5 | SELECT * FROM ORDERS | |
| 6 | fork [A1:A5] | =connect("oracle") |
| 7 | =B6.query@x(A6) |
| A | |
| 1 | =file(sales.txt).import@t() |
| 2 | =A1.select(od>=20240101) |
| 3 | =A2.groups(area,emp;sum(amount):amount) |
| A | |
| 1 | =file(sales.txt).cursor@t() |
| 2 | =A1.select(od>=20240101) |
| 3 | =A2.groups(area,emp;sum(amount):amount) |
| A | |
| 1 | =file(sales.txt).import@tm() |
| 2 | =A1.select(od>=20240101) |
| 3 | =A2.groups(area,emp;sum(amount):amount) |
| A | |
| 1 | =file(sales.txt).cursor@tm() |
| 2 | =A1.select(od>=20240101) |
| 3 | =A2.groups(area,emp;sum(amount):amount) |