01esProc是什么
esProc是什么?
数据业务开发工具
- 结构化和半结构化数据计算和处理
- 面向应用程序员/数据分析师
- 内置轻量级脚本语言SPL
SPL: Structured Process Language

esProc对标什么?
各类用于数据分析的开发工具(及对应的开发语言)

SQL类

Java类

Python类
esProc应对什么痛点?
各类数据分析技术(工具和语言)都存在缺陷
SQL类
- 复杂任务SQL要嵌套多层,难写
- IDE调试功能太差
Java类
- Java/Stream类库缺乏,任务实现难
- ORM技术能力有限
Python类
- 概念混乱,语法一致性差
- 难以集成
esProc带来的价值
增效
- 开发效率提升
- 运算性能提升
降本
- 人力/开发成本降低
- 硬件资源成本降低
02为何选择esProc
为什么选择esProc?
- 1 编辑调试方便
- 2 特色语法与丰富函数库
- 3 多样数据源支持
- 4 轻量易集成
- 5 高性能
编辑调试方便

特色语法
选项语法
pos@z("abcdeffdef","def") //从后往前查找@z
pos@c("abcdef","Def") //忽略大小写@c
pos@zc("abcdeffdef","Def") //组合使用
层次参数
//三层参数:分号表示第一级,逗号第二级,冒号第三级
join(Orders:o,SellerId;Employees:e,EId).groups(e.Dept;sum(o.Amount))
化于无形的Lambda语法
//无形的Lambda语法,更增加[] # ~ 等符号简化运算
stock.sort(tradeDate).group@i(price< price[-1]).max(~.len())
强计算能力
有序计算
//位置筛选与相对位置引用
stock.calc(stock.pselect(price>100),price-price[-1])
分组子集
//针对分组成员再计算
T("employee.csv").group(DEPT).select(~.len()>10).conj()
多层数据处理
//直接用点(.)逐层引用下层数据
json(file("orders.json").read())orders.select(order_details.select@1(product.category=="Electronics") && order_details.sum(price*quantity)>200).new(order_id,order_date)
计算对比每只股票的最长连涨天数
Java
public Map<String, Integer> calculateMaxConsecutiveIncreaseDays(List<StockRecord> stockRecords) {
Map<String, List<StockRecord>> groupedByCode = stockRecords.stream()
.collect(Collectors.groupingBy(
StockRecord::getCode,
Collectors.collectingAndThen(
Collectors.toList(),
list -> {
list.sort(Comparator.comparing(StockRecord::getDt));
return list;
}
)
));
Map<String, Integer> result = new HashMap<>();
for (Map.Entry<String, List<StockRecord>> entry : groupedByCode.entrySet()) {
String code = entry.getKey();
List<StockRecord> records = entry.getValue();
if (records.isEmpty()) continue;
Map<Integer, Integer> consecutiveDaysMap = new HashMap<>();
int cumulativeSum = 0;
for (int i = 0; i < records.size(); i++) {
StockRecord current = records.get(i);
int flag;
if (i == 0) {
flag = 1;
} else {
StockRecord prev = records.get(i - 1);
flag = current.getCl() > prev.getCl() ? 0 : 1;
}
cumulativeSum += flag;
consecutiveDaysMap.merge(cumulativeSum, 1, Integer::sum);
}
int maxDays = consecutiveDaysMap.values().stream()
.max(Comparator.naturalOrder())
.orElse(0);
result.put(code, maxDays);
}
return result;
}
SQL
SELECT CODE, MAX(con_rise) AS max_increase_days
FROM (
SELECT CODE, COUNT(*) AS con_rise
FROM (
SELECT CODE, DT, SUM(updown_flag) OVER (PARTITION BY CODE ORDER BY CODE, DT) AS no_up_days
FROM (
SELECT CODE, DT,
CASE WHEN CL > LAG(CL) OVER (PARTITION BY CODE ORDER BY CODE, DT) THEN 0
ELSE 1 END AS updown_flag
FROM stock
)
)
GROUP BY CODE, no_up_days
)
GROUP BY CODE
Python
Simport pandas as pd
stock_file = "StockRecords.txt"
stock_info = pd.read_csv(stock_file,sep="\t")
stock_info.sort_values(by=['CODE','DT'],inplace=True)
stock_group = stock_info.groupby(by='CODE')
stock_info['label'] = stock_info.groupby('CODE')['CL'].diff().fillna(0).le(0).astype(int).cumsum()
max_increase_days = {}
for code, group in stock_info.groupby('CODE'):
max_increase_days[code] = group.groupby('label').size().max() – 1
max_rise_df = pd.DataFrame(list(max_increase_days.items()), columns=['CODE', 'max_increase_days'])
SPL
stock.sort(DT).group(CODE;~.group@i(CL< CL[-1]).max(~.len()):mids)
esProc的SPL只用一句就搞定了!
丰富函数库
基础函数
- 日期
- 字符串
- …
数学与统计
- 向量
- 回归
- 分类算法
- 统计分析函数
- …
集合运算
- 查找
- 分组
- 连接
- …
文件与网络处理
- CSV/Excel
- XML/JSON
- RESTful接口
- …
数据库操作
- 查询
- 更新
- 事务
- …
大数据
- 游标
- 并行计算
- …
图形绘制
- …
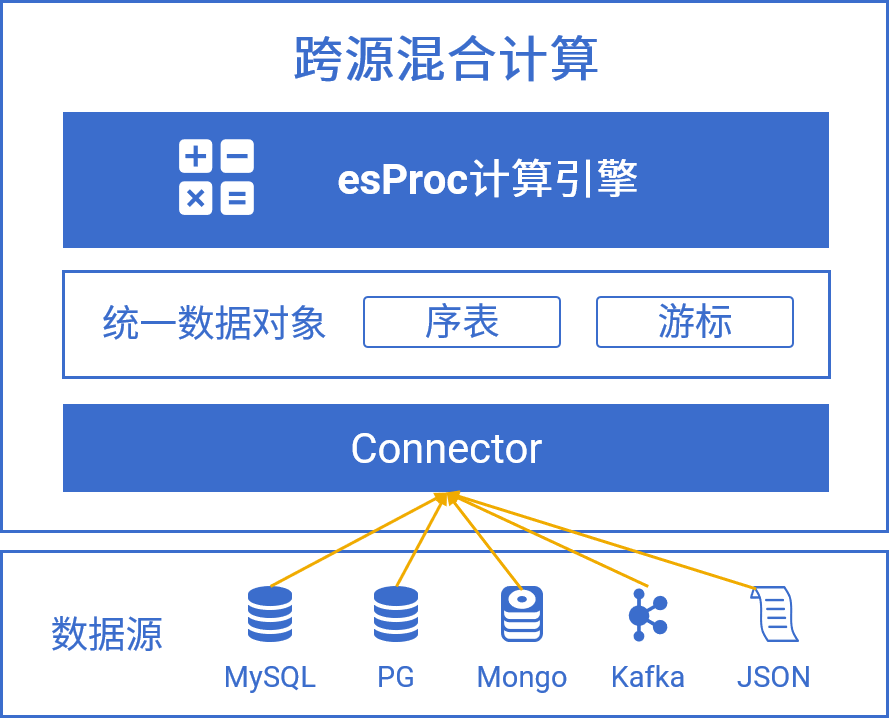
天然多源混算

多样数据源直连混算,Native接口扩展方便
支持的部分数据源列表

多源混算示例
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("SELECT o.order_id, o.user_id, o.order_date, oi.product_id, oi.quantity, oi.price FROM orders o JOIN order_items oi ON o.order_id = oi.order_id WHERE o.order_date >= CURDATE() - INTERVAL 1 MONTH") |
| 3 | =mongo_open("mongodb://192.168.1.15:27017/raqdb") |
| 4 | =mongo_shell@d(A3, "{ 'find': 'products', 'filter': { 'category': { '$in': ['Tablets', 'Wearables', 'Audio'] } }}” ) |
| 5 | =A2.join@i(product_id,A4:product_id,name,brand,category,attributes) |
| 6 | =A5.groups(category;sum(price*quantity):amount) |
MySQL与MongoDB混算
轻量
- JDK1.8 及以上JVM
- 核心部署包不足15M,易分发
- 任何操作系统,包括VM和Container,甚至Android
- 硬件要求低,PC就能跑

应用集成结构
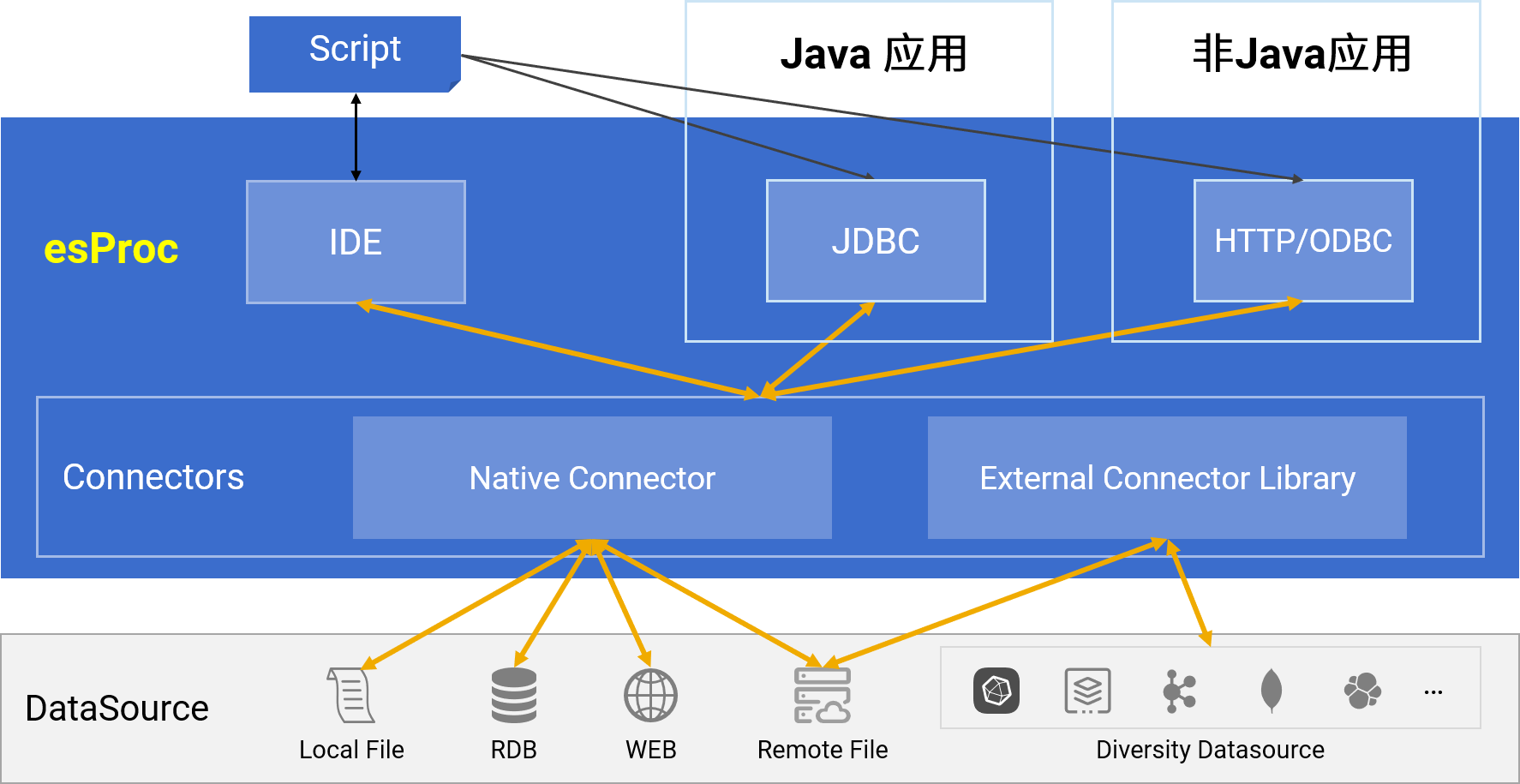
易集成
与各类Java框架/报表工具配合

标准JDBC调用

高性能
存储
esProc提供两种高性能二进制存储格式
集文件
结构简单,
无需定义结构
组表
行列混合存储,支持索引,
需事先定义结构
IO性能超常规数据库15倍以上

算法
内存查找
- 序号定位
- 位置索引
- 哈希索引
- 多层序号定位
- 内表索引
外存查找
- 排序索引
- 带值索引
- 索引预加载
- 批量查找
- 全文检索
遍历技术
- 延迟游标
- 聚合理解
- 有序游标
- 遍历复用
- 预过滤遍历
高效关联
- 外键指针化
- 外键序号化
- 有序归并
- 附表
- 单边分堆连接
算法举例TopN
SQL
//全集TopN,数据库引擎会优化避免大排序
SELECT TOP 10 * FROM Orders ORDER BY Amount DESC
//组内TopN,嵌套后数据库没法优化只能大排序
SELECT * FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY Area ORDER BY Amount DESC) rn
FROM Orders )
WHERE rn<=10
SPL
| A | B | |
| 1 | =file("Orders.ctx").open().cursor() | |
| 2 | =A1.groups(;top(10;-Amount)) | 全集TopN |
| 3 | =A1.groups(Area;top(10;-Amount)) | 组内TopN |
SPL将TopN视为返回集合的聚合运算,避免全排序;
全集和分组时写法类似,都拥有高性能
全集和分组时写法类似,都拥有高性能
03应用场景
报表查询数据准备层
- SPL敏捷计算提升开发效率,避免复杂SQL和存储过程
- 不依赖于数据库的计算能力,代码跨库移植
- 解释执行,天然热切换,报表模块与应用解耦
- 低成本应对没完没了

Java数据逻辑/微服务实现
- 纯Java,和主应用一起打包享受Java成熟框架优势
- 敏捷开发,全面替代Stream/Kotlin/ORM
- 不依赖于数据库的计算能力,代码跨库移植
- 解释执行,热切换,低耦合
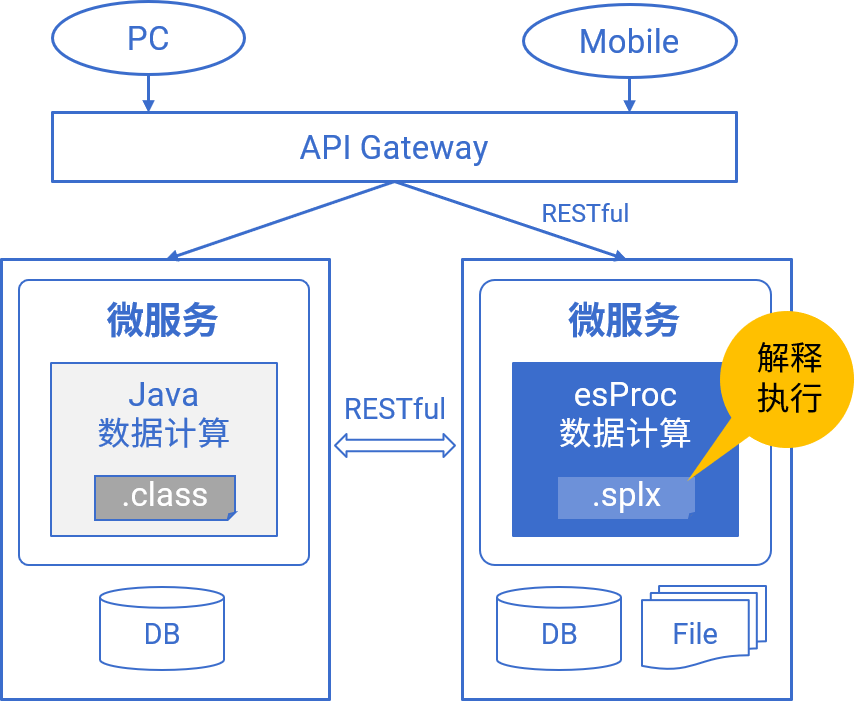
存储过程替代
- 纯Java,和主应用一起打包享受Java成熟框架优势,克服存储过程缺点
- 强大过程计算,易于调试,更高开发效率
- 库外计算,不依赖于数据库,天然可移植
- 无须编译存储过程权限,同时避免应用间耦合,提升安全性和可靠性

数据库减负/消灭中间表
- 非关键中间数据移出数据库存入文件,减少数据库存储负担
- 树状目录更易于管理,降低应用间耦合
- 计算任务移出库外实现,减少数据库计算负担
- 文件访问性能更高,运算性能大幅提高

多样数据源混算/T+0实时全量统计
- 丰富数据源支持:RDB,NoSQL,File,HTTP,...;json等多层数据
- 直接计算,无须入库,保持实时性
- 异构数据库跨库计算,生产库+分析库混合计算实现T+0统计
- 不依赖于数据源的计算能力,天然可移植
嵌入/边缘计算引擎
- 小体积全嵌入,可用于边缘计算场景
- 全面计算功能,包括数学类库,大部分任务无须其它组件
- 简单文件存储,无须数据库
- 可接驳远程大型数据源和存储装置

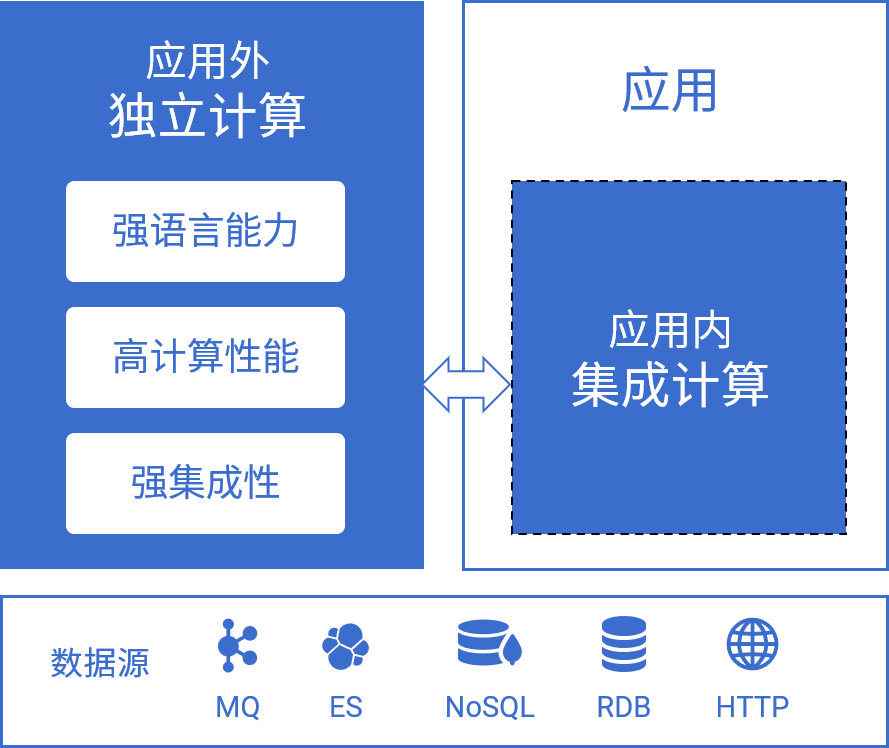
应用外数据清洗准备
- 数据源支持丰富而且一致,方便访问各种无SQL的数据源
- 语言能力强,描述复杂运算比Python更为简捷
- 并行计算,处理大数据时方便性和速度远超Python
- 强集成性,必要时可转移成应用内计算
数据科学家探索分析
- 语言能力强,描述复杂运算比SQL和Python更为简捷
- 比SQL和Python更强的交互性,调试更方便
- 文件存储,数据独立便携,无须数据库就可以分析手边数据
- 并行计算,处理大数据量时方便性和速度远超Python

桌面数据分析

冷数据的热计算
- 历史冷数据装入数据库占用空间,导致运维复杂化,成本高昂,使用频率却很低,但不装入又不能计算
- 临时装入效率低,装入时间远超计算时间
- SPL直接基于文件计算,无需入库,数据不再“冷” ,低廉存储成本提供热计算
