esProc Desktop 是什么?
非专业人员可以学会的
程序语言
桌面数据处理和分析的
工具集
esProc解决什么任务?
- Excel难以直接完成的复杂运算和表格变换
- BI软件无法实施的多步骤交互性数据分析
- 批量或重复性处理(查询/计算/生成/转换)手头的xls/csv/…
现在怎么办?
Excel
操作简单、函数丰富
批量和重复性任务很和繁琐
对复杂的运算支持不足
借助BI软件? Tableau / PowerBI / Qlik / TIBCO / Objects BI …
使用简单、界面流畅美观
计算功能单一,只能做死板的多维分析
借助编程? VBA
完整的编程能力,天然内置于Excel
对表格计算支持太差,简单任务也要大段代码
借助编程? Python
支持表格计算,交互性好,培训班遍地
表格计算不符合自然思维,太多种类表格需要掌握,难度超出非专业人员能力
df = pd.read_csv("../login_data.csv")
df["ts"] = pd.to_datetime(df["ts"]).dt.date
grouped = df.groupby("userid")
aligned_dates = pd.date_range(start=df["ts"].min(), end=df["ts"].max(), freq='D')
user_date_wether_con3days = []
for uid, group in grouped:
group = group.drop_duplicates('ts')
aligned_group = group.set_index("ts").reindex(aligned_dates)
consecutive_logins = aligned_group.rolling(window=7)
n = 0
date_wether_con3days = []
for r in consecutive_logins:
n += 1
if n<7:
continue
else:
ds = r['userid'].isna().cumsum()
cont_login_times = r.groupby(ds).userid.count().max()
wether_cont3days = 1 if cont_login_times>=3 else 0
date_wether_con3days.append(wether_cont3days)
user_date_wether_con3days.append(date_wether_con3days)
arr = np.array(user_date_wether_con3days)
day7_cont3num = np.sum(arr,axis=0)
result = pd.DataFrame({'dt':aligned_dates[6:],'cont3_num':day7_cont3num})
借助数据库? SQL
真正的记录集合,有交互性
环境复杂,不能直接处理桌面文件,非专业人员难以使用
过程式运算复杂度太高,非专业人员难以掌握
WITH all_dates AS ( SELECT DISTINCT TRUNC(ts) AS login_date FROM login_data), user_login_counts AS ( SELECT userid, TRUNC(ts) AS login_date, (CASE WHEN COUNT(*)>=1 THEN 1 ELSE 0 END) AS login_count FROM login_data GROUP BY userid, TRUNC(ts)), whether_login AS ( SELECT u.userid, ad.login_date, NVL(ulc.login_count, 0) AS login_count FROM all_dates ad CROSS JOIN ( SELECT DISTINCT userid FROM login_data) u LEFT JOIN user_login_counts ulc ON u.userid = ulc.userid AND ad.login_date = ulc.login_date ORDER BY u.userid, ad.login_date), whether_login_rn AS ( SELECT userid,login_date,login_count,ROWNUM AS rn FROM whether_login), whether_eq AS( SELECT userid,login_date,login_count,rn, (CASE WHEN LAG(login_count,1) OVER (ORDER BY rn)= login_count AND login_count =1 AND LAG(userid,1) OVER (ORDER BY rn)=userid THEN 0 ELSE 1 END) AS wether_e FROM whether_login_rn ), numbered_sequence AS ( SELECT userid,login_date,login_count,rn, wether_e, SUM(wether_e) OVER (ORDER BY rn) AS lab FROM whether_eq), consecutive_logins_num AS ( SELECT userid,login_date,login_count,rn, wether_e,lab, (SELECT (CASE WHEN max(COUNT(*))<3 THEN 0 ELSE 1 END) FROM numbered_sequence b WHERE b.rn BETWEEN a.rn - 6 AND a.rn AND b.userid=a.userid GROUP BY b. lab) AS cnt FROM numbered_sequence a) SELECT login_date,SUM(cnt) AS cont3_num FROM consecutive_logins_num WHERE login_date>=(SELECT MIN(login_date) FROM all_dates)+6 GROUP BY login_date ORDER BY login_date;
esProc Desktop!
即装即用,非专业人员可独立完成
面向结构化数据
Structured Process Language
代码简洁,远胜VBA、SQL和Python
| A | |
| 1 | =file("login_data.csv").import@tc() |
| 2 | =periods(date(A1.ts),date(A1.m(-1).ts)) |
| 3 | =A1.group(userid).(~.align(A2,date(ts)).(if(#<7,null,(cnt=~[-6:0].group@i(!~).max(count(~)),if(cnt>=3,1,0))))) |
| 4 | =msum(A3).~.new(A2(#):dt,int(~):cont3_num).to(7,) |
- 原生语言支持结构化数据
- 真正的记录集合,只有一种集合
- 直接计算桌面文件
- 语言能力完整
- 简化复杂计算,降低数据分析的技术门槛
超强表格处理能力
合并汇总与拆分
- 列相同的表格合并
- 合并时去除重复的列
- 合并时汇总重复的列
- 追加和累计到汇总表
- 按分类和行数拆分
- ……
集合运算和从属判断
- 简单成员的交并差
- 行式数据求交并差
- 不确定数量的集合求交并差
- 集合相等与从属判断
- 次序无关的集合相等与从属判断
- ……
特殊分类和汇总方法
- 每N个成员分成一组
- 使用相邻数据作为分组条件
- 碰到空行或非空行时分组
- 按数据值的间隔分组
- 将分类内的数据拼接成文字
- ……
扩展与补齐
- 生成连续的区间
- 根据数值将一行扩展出多行
- 拆分文字后扩展成多行
- 在连续值中补足缺失部分
- 每隔N行补足若干空行
- ……
查找与筛选
- 查找某个值的位置
- 使用位置筛选
- 找到第一个或最后一个
- 找到最大最小值
- 选出前N名/后N名
- ……
重复判断、计数与去重
- 判断是否有与自己重复的数据
- 统计重复次数
- 不确定多列一起统计重复次数
- 行式数据去重
- 简单数据去重
- ……
关联与比对
- 关联表引用
- 区间关联
- 二维关联表
- 使用区间范围倒查关联表
- 关联多行数据
- ……
文字与日期处理
- 字符串拆分成多个
- 拆出数字和日期
- 拆出单词
- 计算时间段的重复区间
- 生成一组相同间隔的连续时间点
- ……
格值与汇总值计算
- 使用相邻行和区间计算
- 可能提前终止的累计
- 同类数据连续时使用同类相邻行计算
- 同类数据不连续时使用同类相邻行计算
- 使用同类数据的汇总信息
- ……
排序与排名
- 按指定次序对齐排列
- 指定次序有重复值的对齐
- 将并列排名的成员拼接起来
- 在相同分类内排序
- 分类下的排名
- ……
行列转换
- 固定列的行转列
- 行式表与交叉表互换
- 行列的高层分类互转
- 分类内数据横向拼入列
- 分类数据拼入列时要再分类或排序
- ……
文件提取与生成
- 不确定多行文本构成一个单位
- 指定单元格提取
- 行式和自由式混合结构提取
- 把数据表横向填入列
- 生成多个卡片式表格
- ……
SPL IDE
全功能数据计算集成开发环境
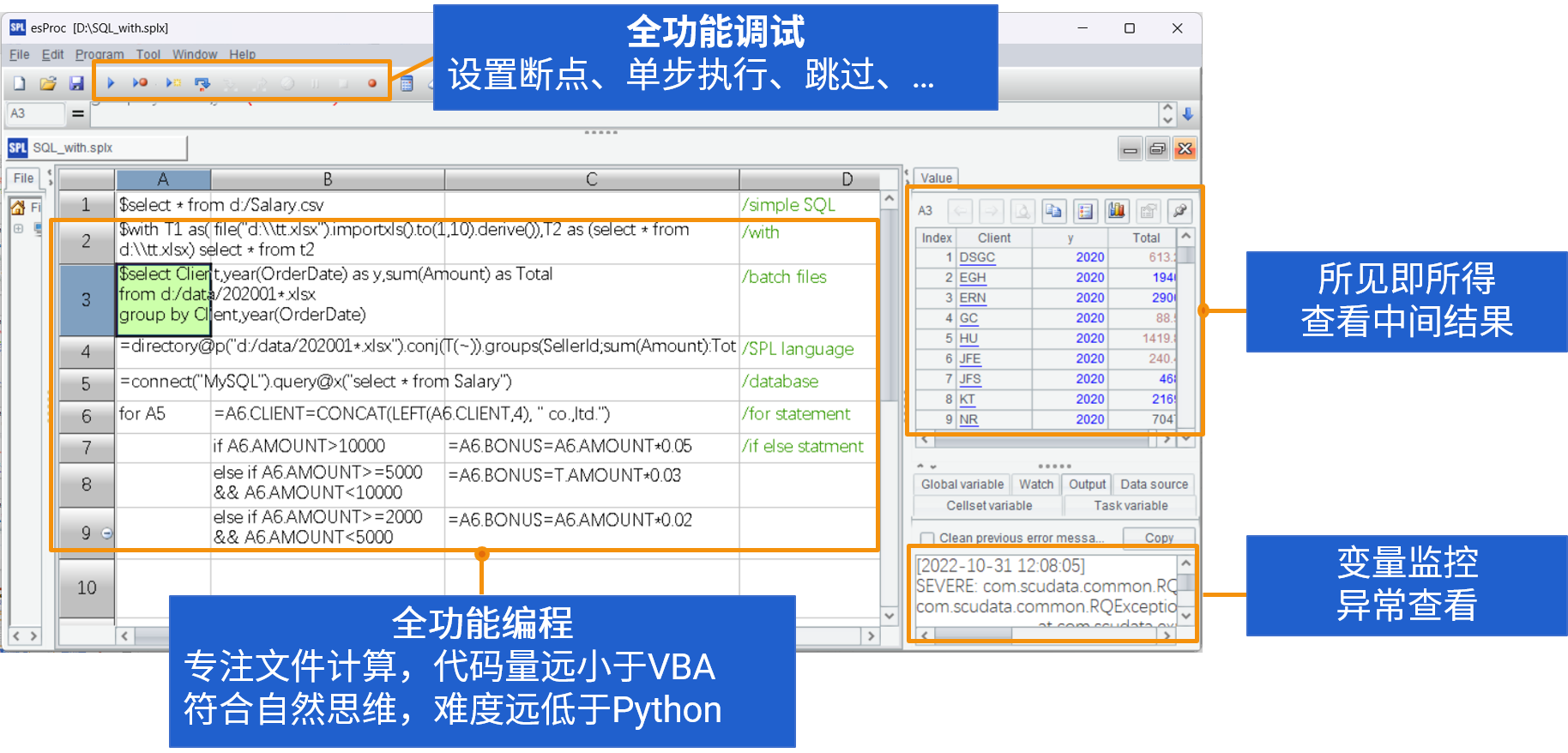
写在格子里的代码

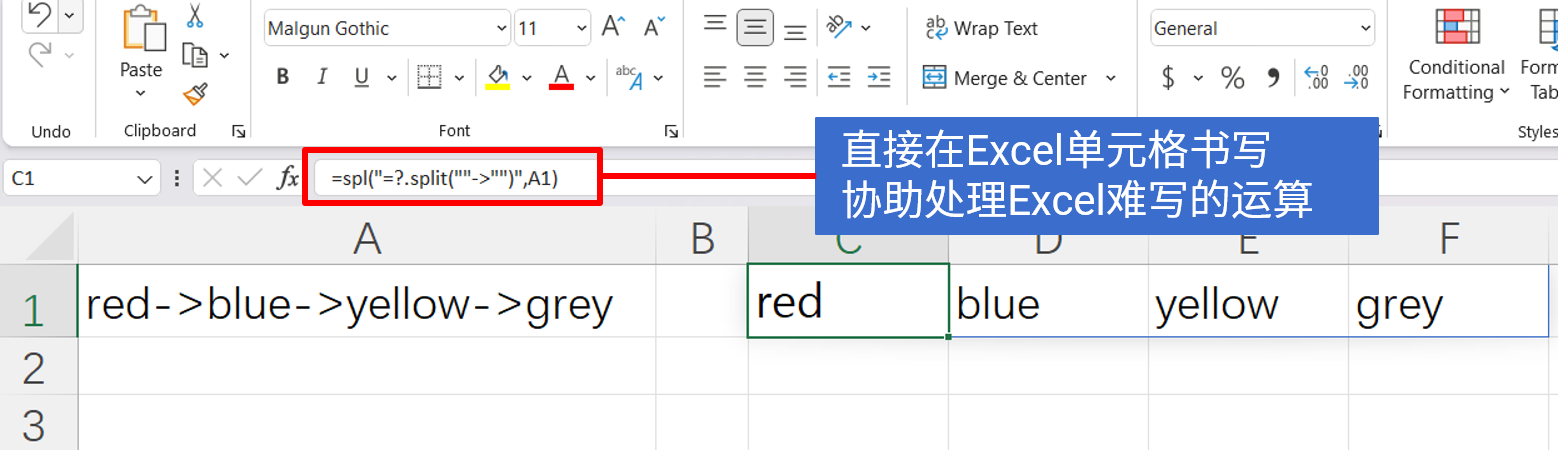
SPL XLL
增强Excel计算能力的插件
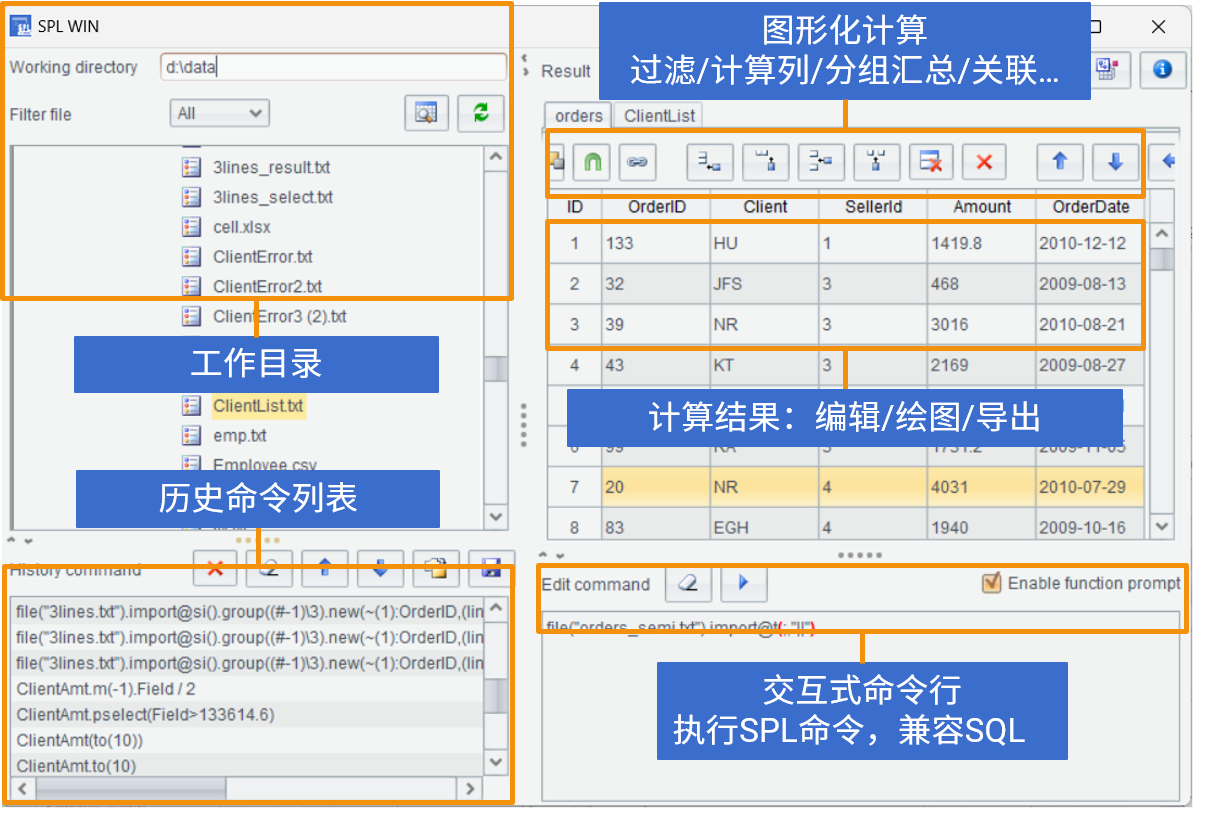
SPL WIN
桌面数据交互式计算工具
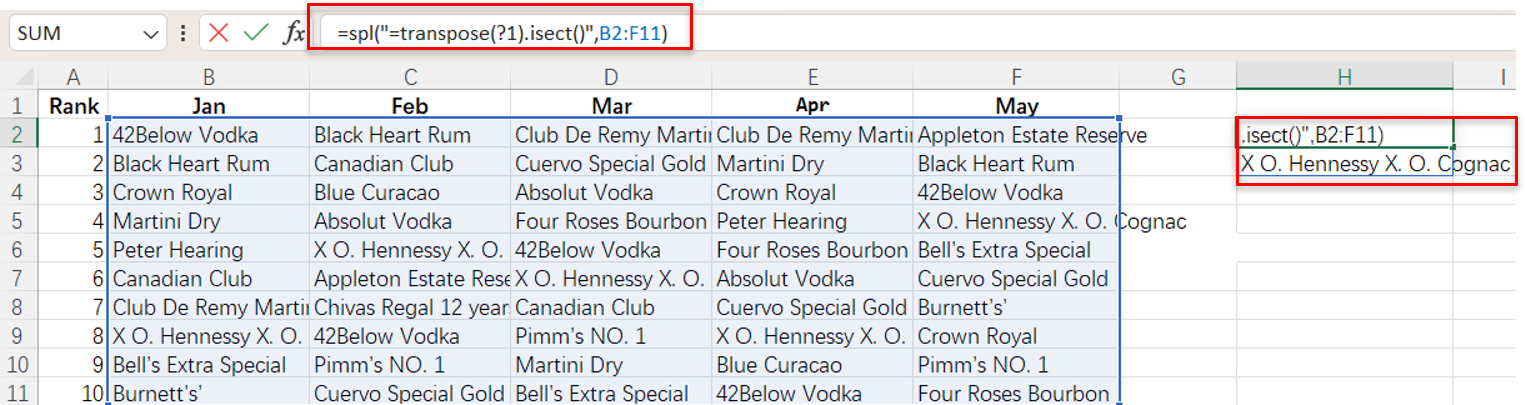
示例
找出每个月都能进top10的明星产品

SPL XLL直接在Excel中计算
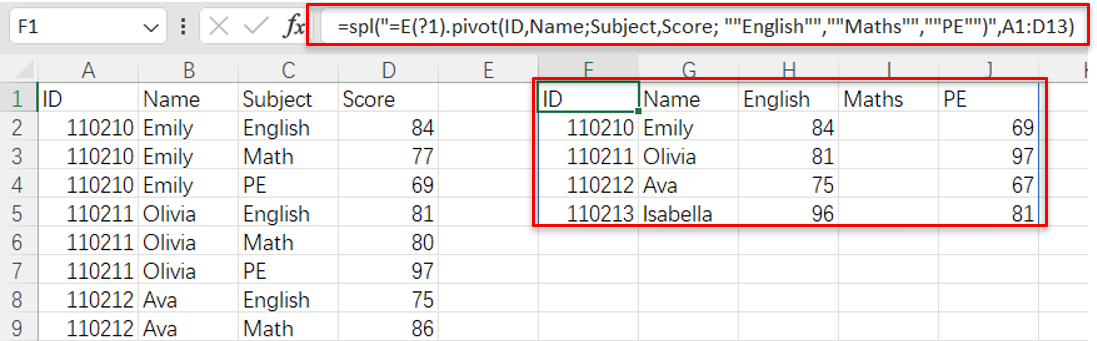
将表格由纵向转置为横向
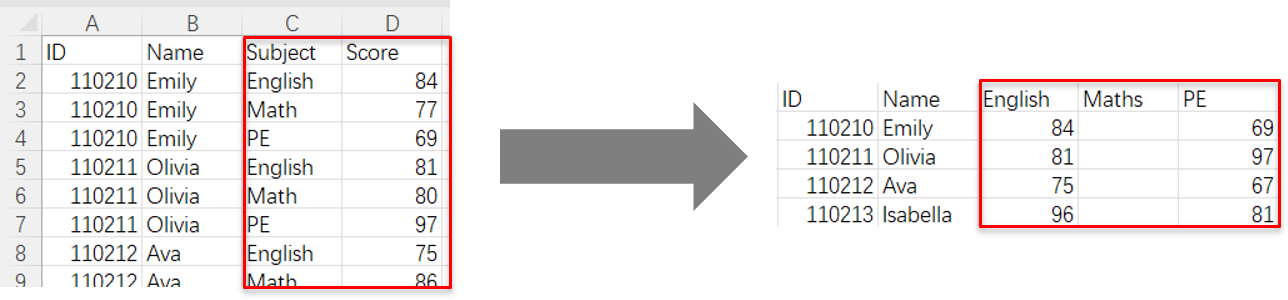
SPL XLL直接在Excel中处理
各车型每月销量及比上期和同期比
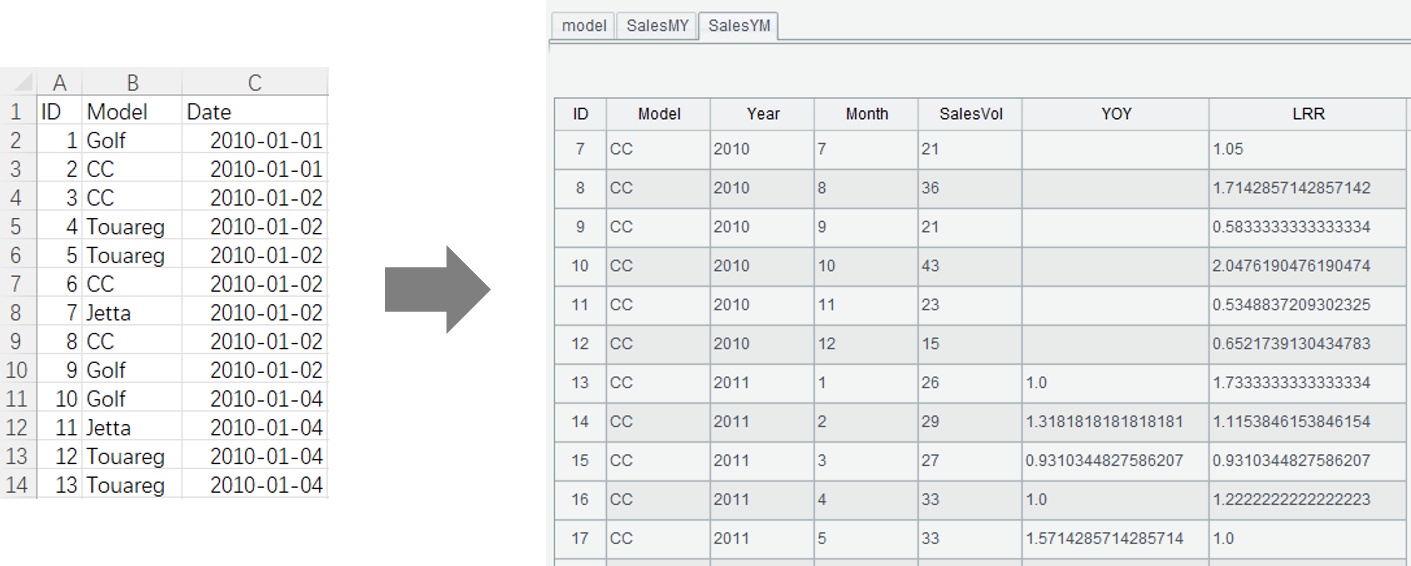
SPL WIN:多步骤交互分析
1. 按车型、月份、年份分组并计数
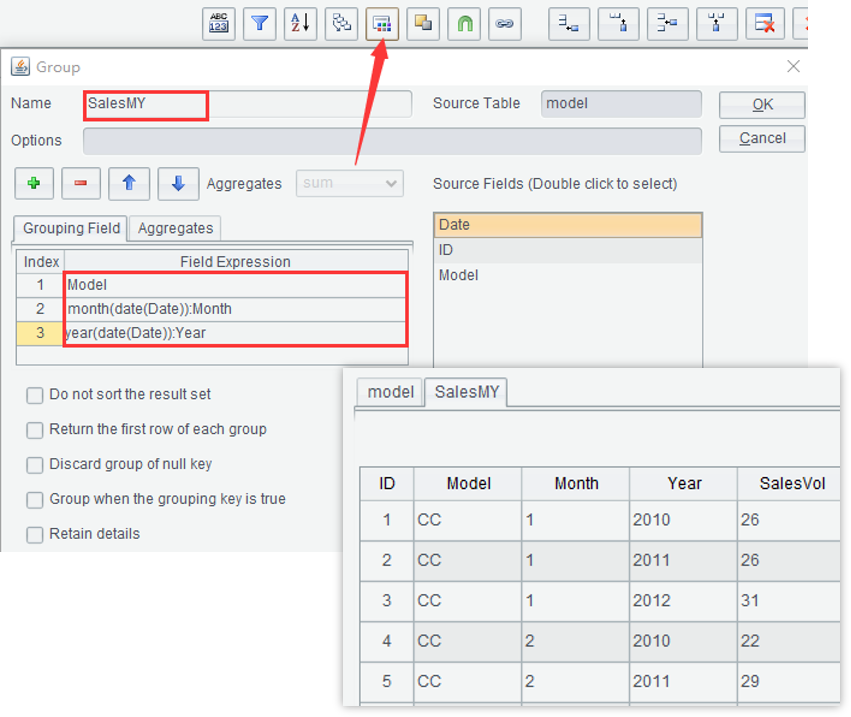
2. 计算同期比:if(Model==Model[-1] && Month==Month[-1],SalesVol/SalesVol[-1],null)
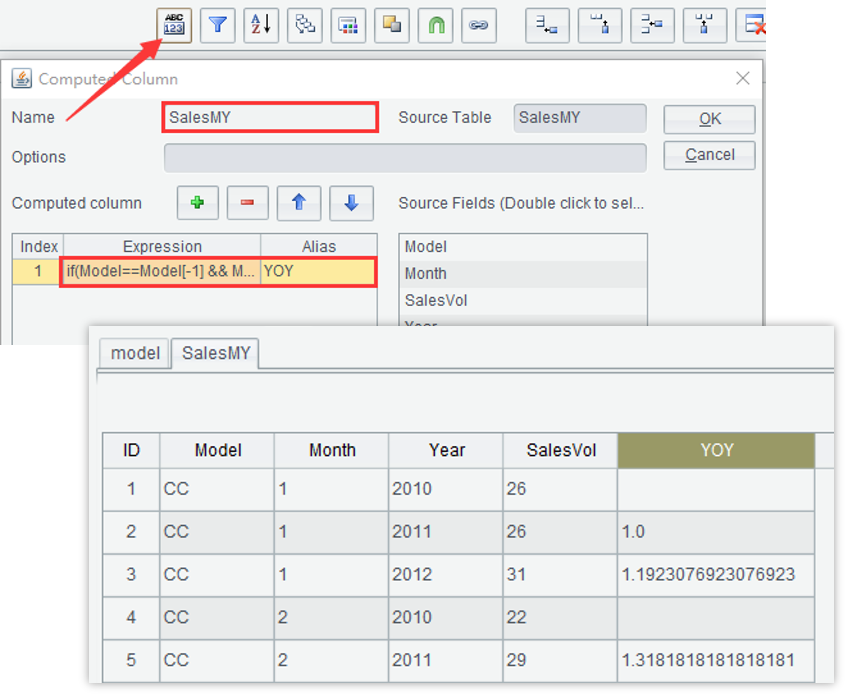
3. 重新按车型、年、月排序
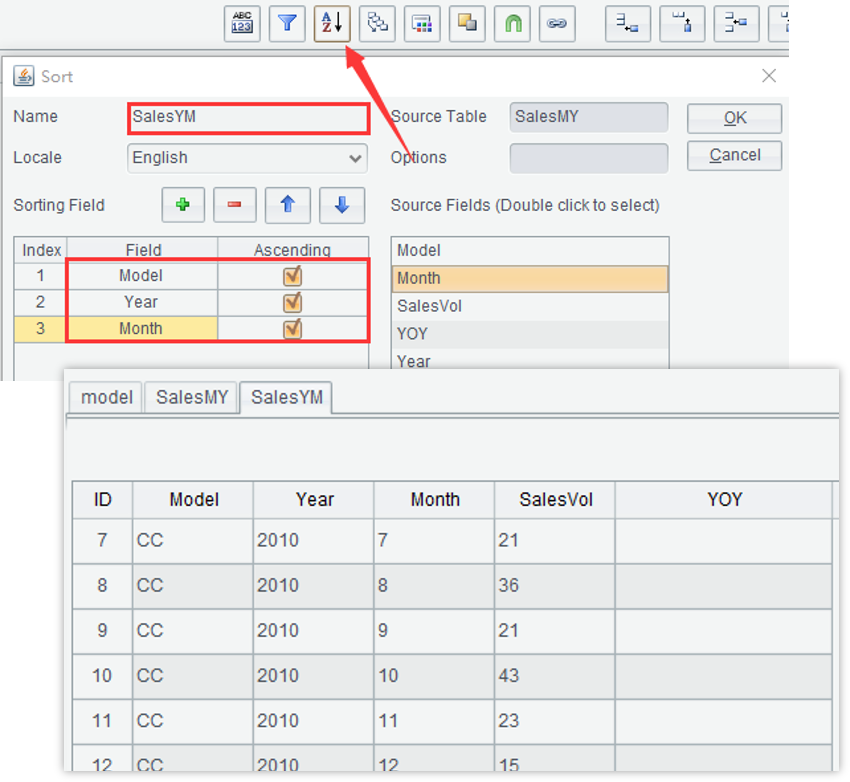
4. 计算比上期: if(Model==Model[-1] ,SalesVol/SalesVol[-1],null)

关联电子表格并计算实际工资
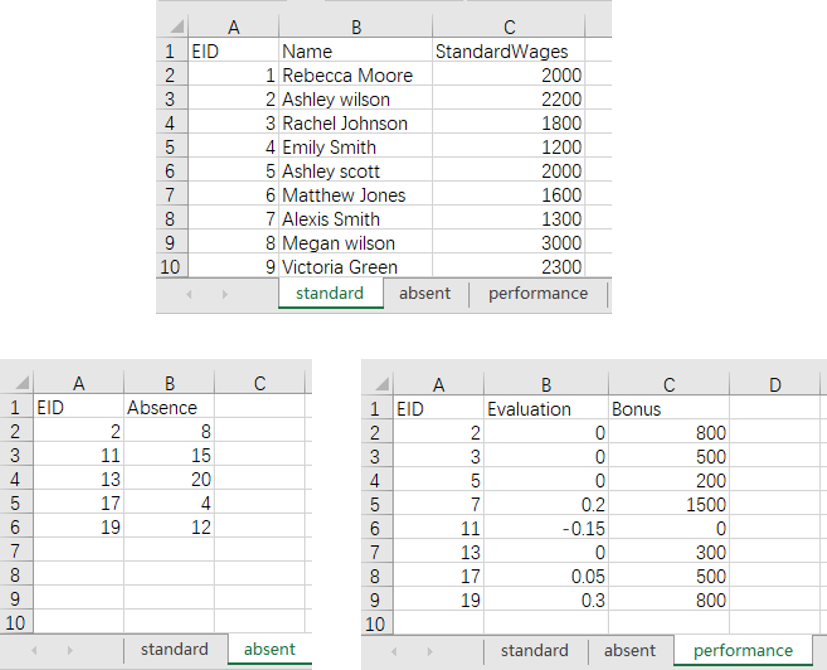
Wage = StandardWages*(1+Evaluation-Absence/40)+Bonus
SPL WIN:多步骤交互计算
1. 读入3个表格
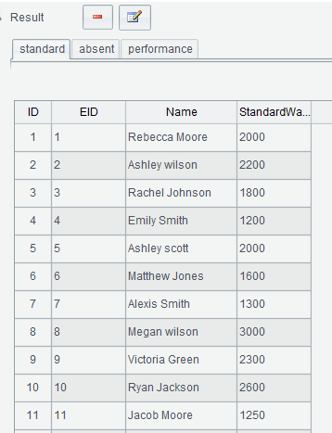
2. 用standard关联absent和performance
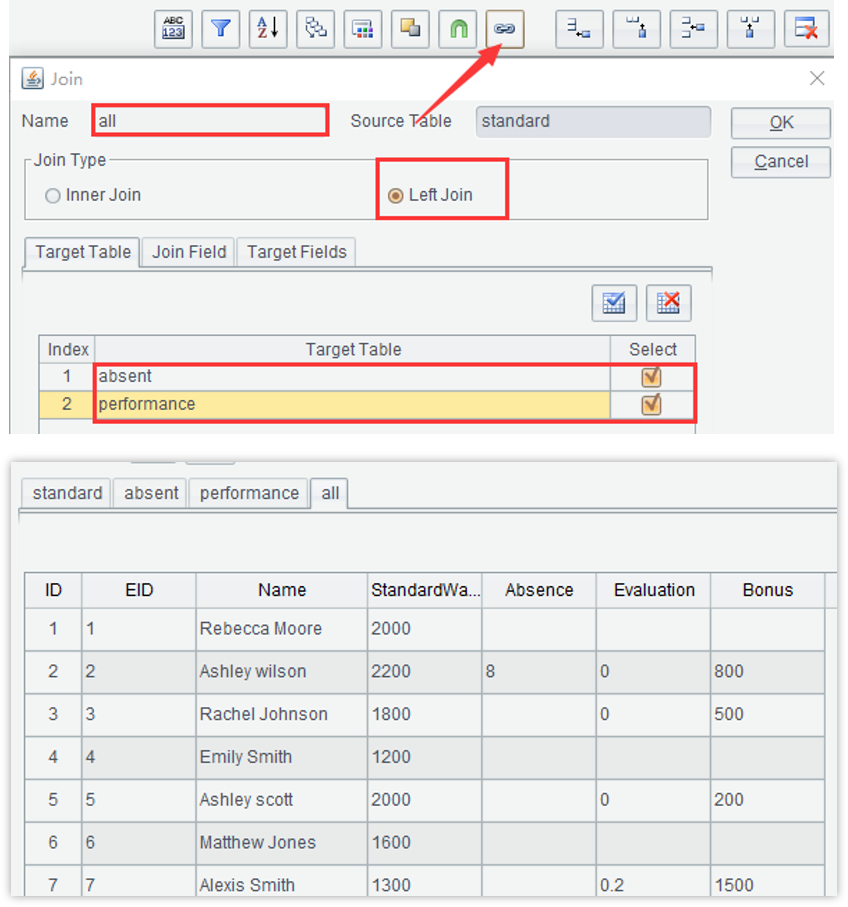
3. 按照公式计算工资

补足Excel中缺失数据:整数列用众数,浮点数列用平均数
SPL IDE:代码实现循环判断逻辑
| A | B | C | |
| 1 | =file("data.xlsx").xlsimport@t() | ||
| 2 | for A1.fname() | =A1.field(A2) | |
| 3 | =B2.sum() | =B2.sum(int(~)) | |
| 4 | =if(B3==C3,B2.mode(),B2.avg()) | ||
| 5 | =B2.(if(~,~,B4)) | >A1.field(A2,B5) | |
| 6 | >file("dataNew.xlsx").xlsexport@t(A1) | ||
从一批卡片式XLS文件中提取出行式数据
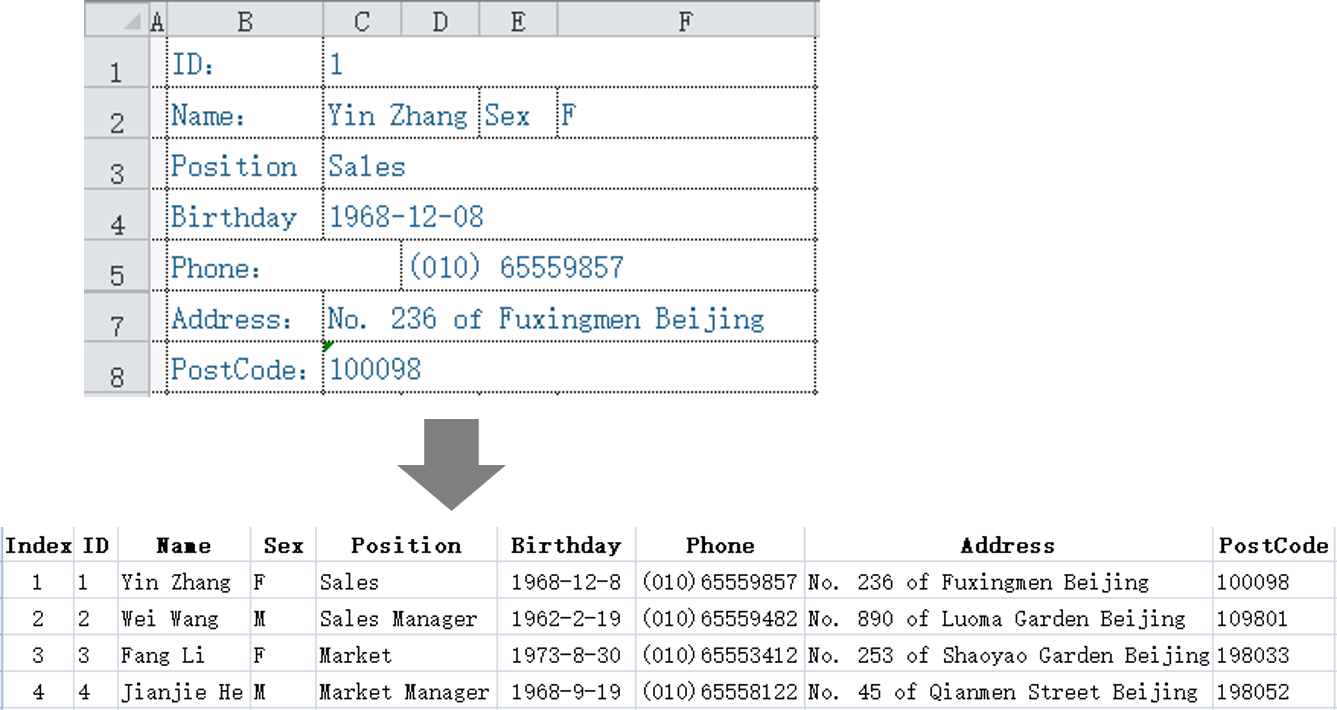
SPL IDE:简洁代码批量解析复杂格式XLS
| A | B | C | |
| 1 | [ID,Name,Sex,Postion,Birthday,Phone,Address,PostCode] | ||
| 2 | [C1,C2,F2,C3,C4,D5,C7,C8] | ||
| 3 | =directory@p("data/*.xlsx") | ||
| 4 | for A3 | =file(A4).xlsopen() | =B2.(B4.xlscell(~)) |
| 5 | =@|C4 | ||
| 6 | =create(${A1.concat@c()}).record(B5) | ||
| 7 | >file("all.xlsx").xlsexport@t(A6) | ||