3.5.4递归查询
在序表中,通过外键式关联,可以引用其它序表的记录,从而实现多个序表间的指针化关联。除此以外,在一个表内,也可以通过外键式关联来引用自身记录,实现自连接。通过自连接实现的数据结构,往往是多层次的树状体系,在这样的结构中查询数据,就需要使用递归查询。
自连接
序表中自连接的使用和多序表连接时没有什么区别。如:
|
|
A |
|
1 |
=file("Geography.txt").import@t() |
|
2 |
>A1.switch(Parent,A1:ID) |
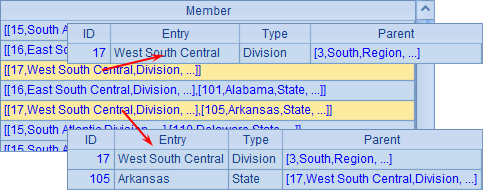
其中,Geography.txt的数据如下,在其中记录了各个层次的地区数据,包括地区,州等,同时通过Parent字段指明当前地区所处的上层地区的编号:
执行自连接后,数据如下:
可以看到通过自连接后产生的多层引用关系。
递归查询记录的各层外键
在自连接后产生的多层外键引用结构中,通过使用r.prior(F,r',n)函数,可以在记录r的外键F中查询外键引用的各层数据。如果指明了r',则会查询到r'出现在外键字段F中为止。在递归查询时,可以根据需要指定递归的最大层次n。如:
|
|
A |
|
1 |
=file("Geography.txt").import@t() |
|
2 |
>A1.switch(Parent,A1:ID) |
|
3 |
=A1.select@1(Entry=="Alabama") |
|
4 |
=A1.select@1(Entry=="South") |
|
5 |
=A1.select@1(Entry=="West") |
|
6 |
=A3.prior(Parent) |
|
7 |
=A3.prior(Parent,A4) |
|
8 |
=A3.prior(Parent,A5) |
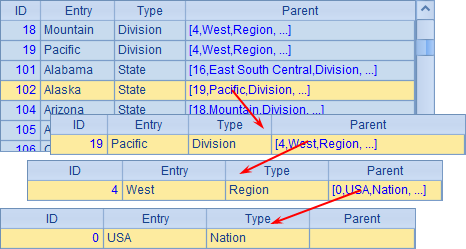
在A6中,查询出Alabama州所引用的各层外键,结果如下:
A7中的结果则查询到South出现在Parent中为止,结果如下:
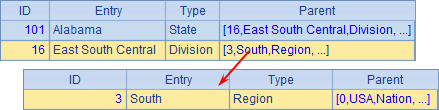
由于Alabama并不在West区域中,因此A8中返回null。
递归查询下层数据
使用prior()函数可以查询记录各层外键所引用的数据,相对应的,也可以使用P.nodes(F,r,n)函数,在排列P中,递归查找所有在外键F中引用到记录的数据。这种查询其实就是在多层外键引用结构中,查找r的下层记录。如:
|
|
A |
|
1 |
=file("Geography.txt").import@t() |
|
2 |
>A1.switch(Parent,A1:ID) |
|
3 |
=A1.select@1(Entry=="South") |
|
4 |
=A1.nodes(Parent,A3) |
|
5 |
=A1.nodes@d(Parent,A3) |
|
6 |
=A1.nodes@p(Parent,A3) |
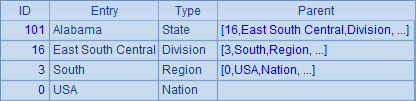
在A4中,查询出所有在South的记录,包括Division和State各层,结果如下:
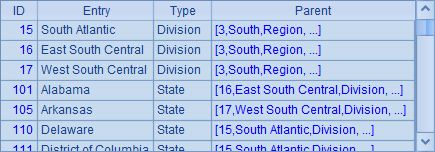
在A5中,nodes()函数中添加了@d选项,此时返回的数据均不再有下层记录,在这里只会返回州数据,结果如下:
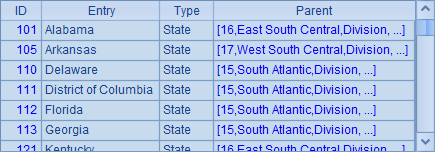
在A6中, nodes()函数中添加了@p选项,此时在返回记录时,将同时返回记录到r的引用层次,结果如下: