3.5.1外键字段
集算器中可以用T.derive()函数为序表添加列,如:
|
|
A |
|
1 |
=demo.query("select EID, NAME, SURNAME, BIRTHDAY from EMPLOYEE") |
|
2 |
=A1.derive(NAME+" "+SURNAME: FULLNAME, age(BIRTHDAY):AGE) |
A1中获取员工信息;A2在A1的序表中添加计算列FULLNAME和AGE后返回,分别算出员工的全名和年龄。
A1中的序表如下:
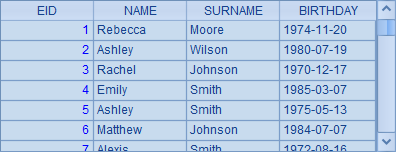
添加计算列后,A2中的序表如下:

了解了如何添加序表的计算列,就可以来看计算列与表间关联的关系了。
在数据库中,在表与表之间经常会存在关联关系,而在集算器中,可以直接用记录引用作为序表中的数据,这样就能体现表间的关联,使得数据的检索和展现简单而结构明晰。
如果我们通过T.derive()来添加列,使这一列的数据类型为另一个表的记录引用或是排列引用,就能构成外键字段,从而实现表间关联,如:
|
|
A |
|
1 |
=demo.query("select * from CITIES") |
|
2 |
=demo.query("select STATEID, NAME, ABBR, CAPITAL from STATES") |
|
3 |
=A1.derive(A2.select@1(STATEID==A1.STATEID):State) |
|
4 |
=A3.derive(State.ABBR:SA) |
|
5 |
=A2.derive(A1.select(STATEID==A2.STATEID):Cities) |
A1和A2分别取出数据库表STATES和CITIES的数据:
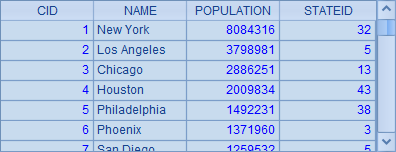
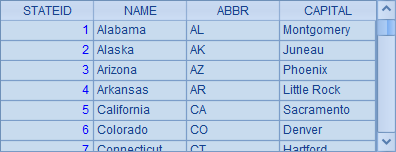
CITIES通过STATEID字段和STATES关联。数据库中的这种存储模式可以使得数据保持一致,易于维护,同时也节省了存储空间。
A3在CITIES中添加State字段作为外键,存储城市所在州的记录。A4中再为城市数据添加SA字段,列出所在州缩写,以方便后面的查看。A5则在州数据中添加Cities字段作为外键,存储每个州中的各个城市记录。
执行后,A4中的数据如下:

其中的State字段为州信息的记录,可以双击查看。
A5中的数据如下:
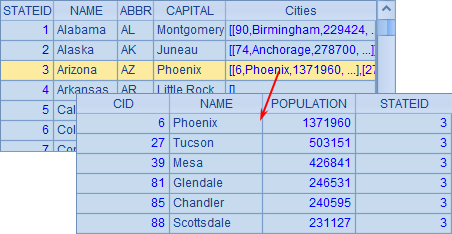
其中的Cities字段为该州的城市记录,也可以双击查看。
可以发现,通过添加外键字段的方式,无论是A4还是A5中的数据,实际上都已经包含了源数据库中STATES和CITIES这两个表的信息,实现了表间关联。需要注意的是,同样是外键字段,它们的类型是不同的:在A4中,外键State的数据是记录;而A5中,外键Cities的数据是排列,即记录的序列。
实际上,STATES表中的STATEID这样的字段,经常是表的主键,在将另一个表如CITIES,通过主键与STATES关联时,也可以使用switch函数。相关的使用方法,请看3.6主键与索引功能。