3.4.4枚举分组
设定一个条件表达式字符串构成的序列E后,还可以用P.enum(E,y) 函数来将一个序列P中的所有成员分组,运算时,将依次对每个成员计算表达式y,判断结果第几个条件,并将P中的成员分配到对应的组中,默认情况下,P中的每个成员只会置入第1个满足条件的组中。如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,GENDER, BIRTHDAY,SALARY from EMPLOYEE") |
|
2 |
[?>=15000,?>=12000,?>=9000] |
|
3 |
=A1.enum(A2,SALARY) |
A1中查询出的序表以及A2中的枚举条件序列如下:


A3中,根据条件序列,枚举分组的结果如下:

可以发现,枚举分组的每组中, SALARY并不相等,而是满足同一个条件。同样,虽然满足第1个条件的数据同样也满足后面2个条件,但默认只分到满足的第1个条件所在的组。对于不满足所有条件的数据,则不会被分到任何1组中,如第1条和第4条数据等。
和penum相似,枚举分组时,也可以在最后添加null条件,将所有不满足前面条件的记录置入;也可以使用enum@n,效果是类似的,如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,GENDER, BIRTHDAY,SALARY from EMPLOYEE") |
|
2 |
[?>=15000,?>=12000,?>=9000] |
|
3 |
=A1.enum@n(A2,SALARY) |
|
4 |
[?>=15000,?>=12000,?>=9000,null] |
|
5 |
=A1.enum(A4,SALARY) |
A3和A5中的结果是相同的:

和上例的结果对比,可以发现,用enum@n函数,或者在条件序列最后添加null,都将把所有不满足前面条件的数据,分到一个分组中。
缺省情况下,enum函数在计算时假定不会有重复分组,即P中成员不会同时满足两个条件表达式。如果需要重复分组时,需要添加@r选项。如:
|
|
A |
|
1 |
=demo.query("select EID,NAME,GENDER, BIRTHDAY,SALARY from EMPLOYEE") |
|
2 |
[?>=15000,?>=12000,?>=9000] |
|
3 |
=A1.enum@r(A2,SALARY) |
A3中用enum@r重复枚举分组,结果如下:
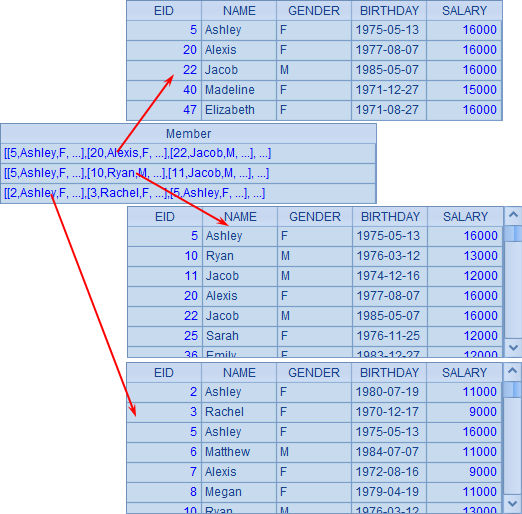
从分组结果中可以发现,采用重复分组后,第1组中的成员出现在全部3组中,而第2组的成员也重复出现在了后两组中。