3.3.3在序表中计算排名
在计算排名时,有两种常见方式:计重排名,与不计重复的排名。如比赛中出现了2个并列第1名的选手,如果计算重复名次,那么排在他们下一位的选手就是第3名了;如果不计重复排名,那么将不考虑并列名次多占的位置,排在他们下一位的记为第2名。在集算器中,用rank可以计算排名结果,用rank可以计算单个数据的排名,如果添加@i选项,将去除重复值后再计算名次,如:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.ranks(SALARY) |
|
3 |
=A1.ranks@i(SALARY) |
|
4 |
=A1.rank(10000,SALARY) |
|
5 |
=A1.rank@i(10000,SALARY) |
A2中计算出所有员工的薪水排名,A3中计算出员工薪水的不计重复排名,A2和A3中的结果如下:


我们再来看一下A1中的员工数据:
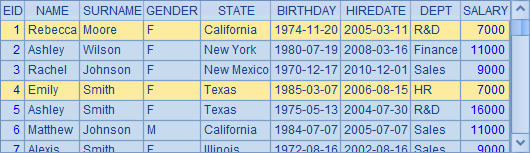
对比后可以发现,薪水相同的员工,如Rebecca和Emily,同样方法中计算出的薪水排名也是相同的。但是A3中计算出的名次显得靠前很多,这是由于不计重复的排名方式中,并列的名次不会影响后面的名次。实际上,A2中的排名结果更能反映出真实的排位。
A4中计算出10000在员工的薪水中可以排到的名次;A5中计算不计重复排名时,10000在员工薪水中的排名。A4和A5中结果如下:
![]()
![]()
同样,不计重复的排名,结果会比普通排名更靠前。在计算rank@i和ranks@i时,类似于先将结果用id函数列出所有不重复的结果,再计算排名。