3.2.3分组汇总
在上一节,我们看到了将序表中的记录分组后,再利用分组后的结果汇总计算的例子。使用group函数,也可以直接获得分组后的计算结果,而无需分步,如:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.group(DEPT;~.count():Count,~.sum(SALARY):TotalSalary) |
|
3 |
=A1.group(DEPT;~.count(GENDER=="M"):Male, ~.count(GENDER=="F"):Female) |
|
4 |
=A1.group(DEPT;round(~.avg(age(BIRTHDAY)),2):AverageAge) |
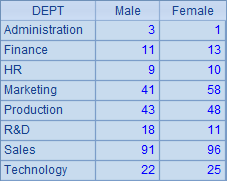
A2和A3中直接根据DEPT字段分组并汇总,结果和分步处理时是相同的:

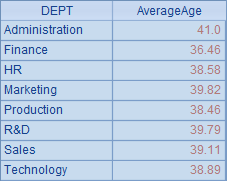
A4中则计算出了各部门员工的平均年龄:
集算器也提供了用累计方法来计算分组汇总值的函数groups,如:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.groups(DEPT;count(~):Count,sum(SALARY):TotalSalary) |
|
3 |
=A1.groups(DEPT;count(GENDER=="M"):Male, count(GENDER=="F"):Female) |
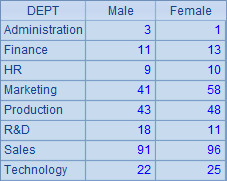
A2和A3中直接根据DEPT字段分组汇总,注意写法和前面的例子略有不同,"~.”可以省略,结果和先分组再汇总时是相同的:

直接用groups函数分组汇总时,返回的结果同样是序表。用groups函数计算分组汇总时,并不会记录每个分组中的数据,仅根据分组表达式计算累加。不过和前面用group函数计算分组汇总相比,用groups函数效率更高。
需要注意的是,使用groups直接累计分组汇总时,只能用sum/count/max/min/top/avg/iterate等简单聚合函数。更复杂的分组汇总,只能用group函数,而不能用groups。
特别的,在汇总函数中可以用top来求出最小的n个结果,如:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.groups(DEPT;top(3,age(BIRTHDAY))) |
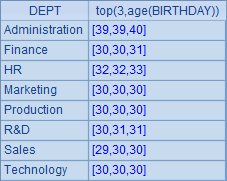
A2中分组统计出每个部门中,最年轻的3个人的年龄:
在用top汇总时,只能获得最小的n个结果。如果需要统计最年长的3个人的年龄,可以用下面的方法:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.groups(DEPT;top(3,BIRTHDAY)) |
|
3 |
=A2.new(DEPT,#2.(age(~))) |
|
4 |
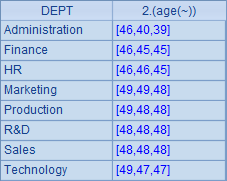
=A1.groups(DEPT;top(-3,age(BIRTHDAY))) |
A2中先统计出每个部门中最小的3个生日,再在A3中进一步计算出年龄。A2和A3中结果如下:

更方便的方法是如A4中的表达式,用top(-n)直接计算取出年龄最大的3位,结果如下:
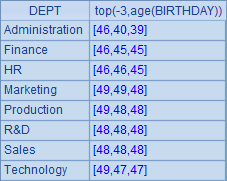
A4和A3中计算出的数据是相同的。