3.2.1计算唯一值
在序表的所有记录中,有一些字段的值是各不相同的,如编号等。而更多的字段,有可能出现重复值,有时会需要列出所有不同的值,可以使用id函数,如:
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
=A1.id(SalesID) |
|
3 |
=A1.id(PName) |
其中,A1中序表如下,窗口中只显示了部分数据:
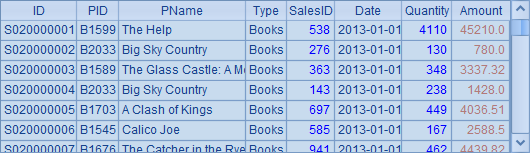
在A2中,取出所有不同的销售员编号SalesID,A3中取出所有不同的书籍名称PName,A2和A3中的结果如下:


从结果中可以发现,用id函数计算唯一值时,会将结果升序排序。
实际上,id函数返回的结果,类似于SQL中的distinct语句,如:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.id(STATE) |
|
3 |
=demo.query("select distinct STATE from EMPLOYEE") |
A1中从数据库中选出了员工资料表如下:
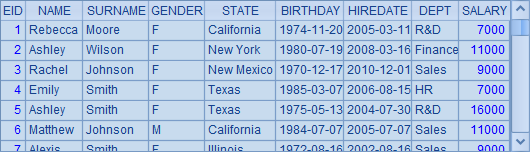
A2中用id函数从A1的序表中选出所有不同的州,而A3中用distinct语句从数据库中获取结果。A2和A3中的结果如下:


可以看到,两种方法返回的数据相同。但是id函数返回的是序列,而用SQL语句从数据库返回的是序表。
有些时候,我们不希望将原始顺序打乱,此时可以添加@o选项,如:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.id@o(STATE) |
此时,A2中的结果如下:

从结果中可以发现,id@o函数在执行时,不排序,但只是直接去除相邻的同值数据,结果中有可能出现重复的值,如上面结果中的Texas和California等。
使用id函数时,也可以不选用字段,而是列出某个表达式的所有不同结果:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.id@o(age(BIRTHDAY)) |
A2中列出了员工的年龄:
