1.7.2 常用函数选项
在集算器中,一些函数选项是比较常见的,可以使用在多个函数中。
Ø @1与@a
在定位、选出以及关联函数中,经常用到@1和@a这两个选项,如A.pos(), A.select(), A.pmax(), A.pselect(), A.minp(), P.align()等。
使用@a选项,可以使默认返回第1个查询结果的函数,返回所有满足条件的结果。与@a相反,添加@1选项后,默认返回多个成员的函数,只会返回找到的第1个结果。
我们通过一些例子来了解一下@a与@1选项的使用:
|
|
A |
|
1 |
[1,2,3,4,3,2,1,2,3,2,1] |
|
2 |
=A1.pos(2) |
|
3 |
=A1.pos@a(2) |
|
4 |
=A1.pselect(~==1) |
|
5 |
=A1.pselect@a(~==1) |
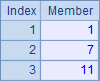
A2,A3,A4和A5中的结果分别如下:
![]()

![]()
|
|
A |
|
1 |
=demo.query("select * from CITIES") |
|
2 |
=A1.select(left(NAME,1)=="C") |
|
3 |
=A1.select@1(left(NAME,1)=="C") |
|
4 |
=A2.align([6,35,40],STATEID) |
|
5 |
=A2.align@a([6,35,40],STATEID) |
A2中选出名称首字母为C的城市:
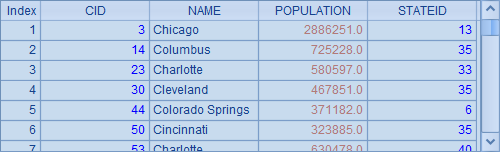
A3中找出第1个首字母为C的城市:
![]()
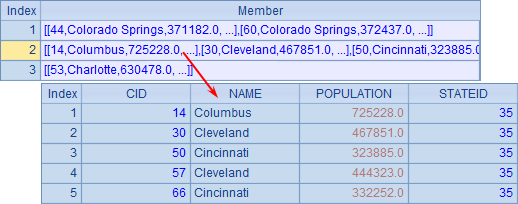
A4中找出州编号为6,35及40的第1个城市:

A5中找出所有州编号为6,35及40的城市,并将它们按所在州分组:
顺便说明一下,由于数字1与小写字母l不易区分,因此在集算器的选项中,大多数都是使用数字1。
还需要了解的是,同样的选项,在不同的函数中可能代表不同的含义。如@a用在定位函数中表示返回全部,而用在写文件函数f.write()或f.export()中时,表示追加。
Ø @z
在一些与顺序有关的排序、定位、选出等函数中,经常使用@z选项,如A.rank(), A.sort(), A.pos(), A.pselect(), A.select()等。
|
|
A |
|
1 |
[1,2,3,4,3,2,1,2,3,2,1] |
|
2 |
=A1.pos@z(2) |
|
3 |
=A1.sort@z() |
|
4 |
=demo.query("select * from CITIES") |
|
5 |
=A4.select@z(STATEID:5) |
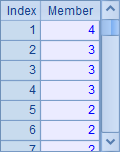
使用@z选项后,在定位或选出时,在序列或序表中,会从后向前执行。因此,在例子中A2返回最后一个2的位置:
![]()
A3中返回从大到小排序的结果:
A5中获取的记录也是从后向前排的:
Ø @b
在一些定位、选出等函数中,经常使用@b选项,如A.pos(), A.pselect(), A.select()等。使用@b选项时,会在查找时使用二分法,二分法具有更高的查找效率,但是要求A必须是有序的,否则有可能获得错误的结果。
|
|
A |
|
1 |
=demo.query("select * from CITIES") |
|
2 |
=A1.select@b(STATEID:5) |
|
3 |
=A1.sort(STATEID) |
|
4 |
=A3.select@b(STATEID:5) |
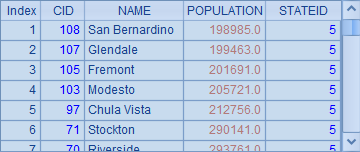
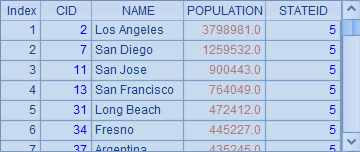
由于A1中的数据并非按州代码排序的,因此A2中使用了@b选项后,用二分法只找到1条结果:
![]()
而A3中对数据进行了排序,A4中才能获得正确的结果:
当在文件读写函数中用到@b,就是另外的情况了,如f.import(), f.export(), f.cursor()等。此时,说明读入或写出的是二进制文件。在集算器中,二进制文件称为集文件,扩展名通常为btx,它的存储空间更小,读写速度更快,使用集文件更有效率。