3.6.1find和pfind
主键,是数据库表中经常见到,主键字段的值被用来在表中唯一标识一条记录,因此主键字段的值是不能重复的,在很多数据库中对此作了强制规定。
在集算器中,序表中类似于主键的字段可以有多个,这些字段均称为键,需要有着确定的次序。在序表中,所有键字段的取值称为主键。序表假定主键值在记录中是唯一的,但并没有硬性检查,主键值重复了也不会报错。T.pfind(k)和T.find(k)函数,都可以用来根据主键的值k在序表T中查找记录,其中pfind返回找到的第1条记录的序号,find返回找到的第1条记录。在函数中,根据T中键的个数,k可能是单值或序列。
如果需要将主键设为指定的字段,则需要使用T.keys(Fi,…) 函数,设置序表T的主键为Fi,…。在用create(Fi,…) 函数创建空序表时,可以在某些字段名前添加#表示该字段为键。如=create(#OrderID,Client,SellerId,Amount,OrderDate),在新建的空序表中,OrderID是主键。
在序表中查找记录,我们通常使用常规的定位函数T.select() 和T.pselect()这两个函数,下面我们来看一下pfind和find跟它们的对比。
在这里,将使用demo数据库中的EMPLOYEE表作为需要查找的序表,并在其中添加FullName字段,准备用员工的全名来查找:
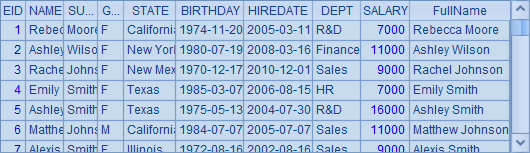
为了更明显地发现用主键来查找数据的性能优势,我们随机生成10000个全名,并根据这些全名,分别用pselect和pfind来查找,计算两种方法的耗时:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.derive(NAME+" "+SURNAME:FullName) |
|
3 |
=10000.(A2(rand(A2.len())+1).FullName) |
|
4 |
=now() |
|
5 |
=A3.(A2.pselect(FullName:A3.~)) |
|
6 |
=interval@ms(A4,now()) |
|
7 |
=now() |
|
8 |
>A2.keys(FullName) |
|
9 |
=A3.(A2.pfind(A3.~)) |
|
10 |
=interval@ms(A7,now()) |
A5和A9中基于相同的数据,分别使用pselect和pfind函数在序表中查找记录的位置,其中,使用pfind之前,需要用keys函数设定序表的主键。A6和A10中分别计算出耗费的毫秒数如下:
![]()
![]()
而A5与A9中的查找结果是相同的:

用类似的方法,还可以对比select与find函数,为了与find函数保持一致,在select函数中使用了@1选项,同样只找到第1个结果即返回:
|
|
A |
|
1 |
=demo.query("select * from EMPLOYEE") |
|
2 |
=A1.derive(NAME+" "+SURNAME:FullName) |
|
3 |
=10000.(A2(rand(A2.len())+1).FullName) |
|
4 |
=now() |
|
5 |
=A3.(A2.select@1(FullName==A3.~)) |
|
6 |
=interval@ms(A4,now()) |
|
7 |
=now() |
|
8 |
>A2.keys(FullName) |
|
9 |
=A3.(A2.find(A3.~)) |
|
10 |
=interval@ms(A7,now()) |
A6和A10中分别计算出耗费的毫秒数如下:
![]()
![]()
A5与A9中的查找结果仍然是相同的:
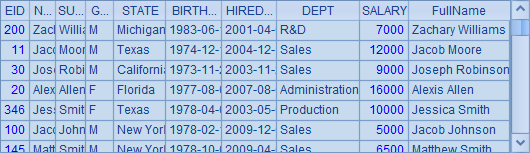
从上面的对比不难看出,基于主键的查找函数,效率明显高于常规的定位函数。