【数据蒋堂】第10期:报表的数据计算层

我们在上一期已经解释了报表应用结构中数据计算层的必要性,以及可以使用报表工具自定义数据源接口来实现计算层。在计算层中要完成一些复杂的计算逻辑,因此要有可编程的能力,而基于自定义接口可以采用报表工具的宿主语言(即用于开发报表工具的程序设计语言)进行开发,在功能方面没有问题,不过,实际应用中却仍有不少缺陷。更好的方式是实现一个显式的数据计算层,在其中提供可解释执行的脚本功能,把数据源计算独立出来。
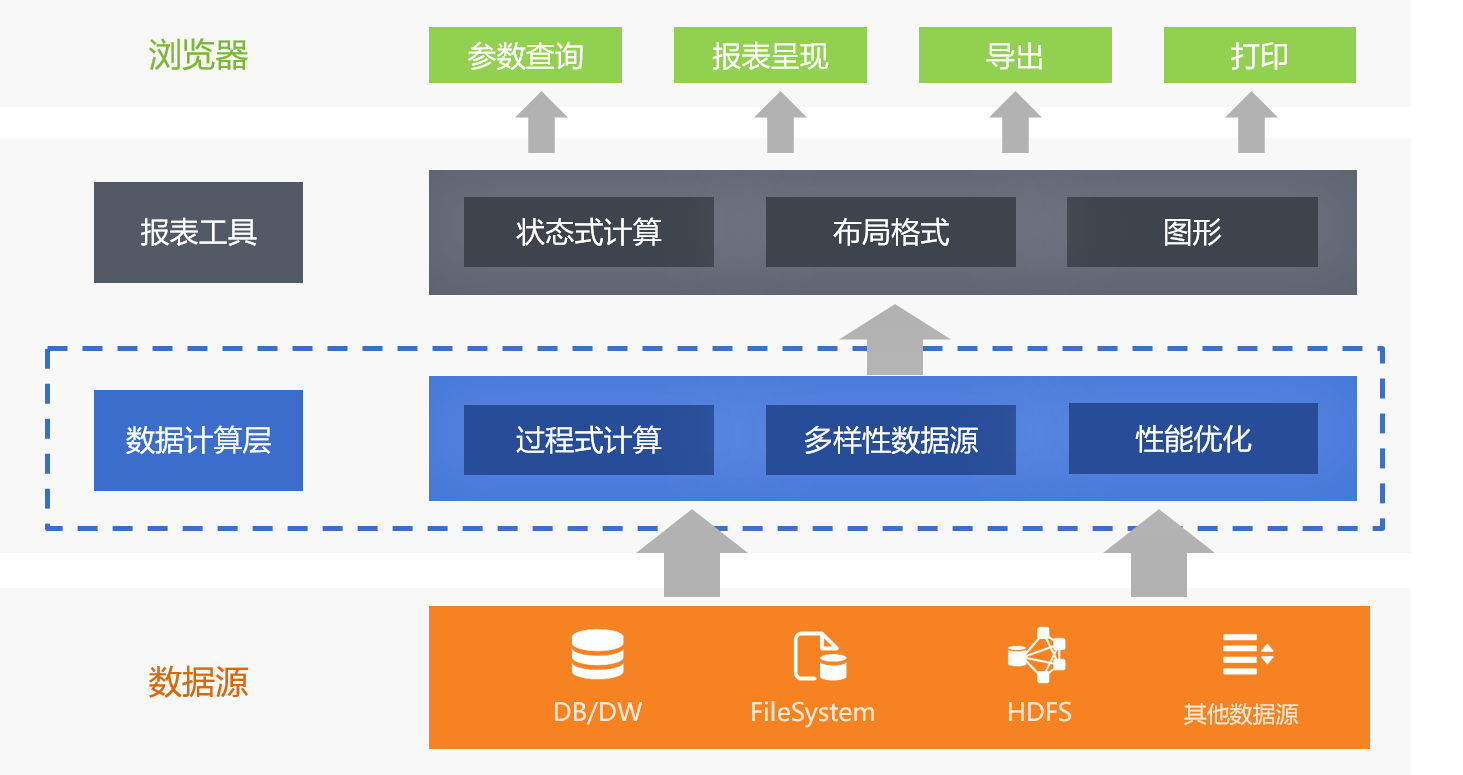
我们从四个方面来分析后者的优势。
代码编写
报表工具的宿主语言一般是Java、C#等高级语言,这类语言针对结构化数据集的支持很有限,虽然都能做,但却非常繁琐,简单做个求和运算都需要写数行代码的循环来实现。而报表数据源处理则大量涉及批量数据运算,采用高级语言开发时会导致动辄数百行的冗长代码,编写和调试都很困难。
专门为数据计算设计的脚本则能够提供丰富的结构化数据集运算功能,可以很方便地实现批量数据计算。代码更短不仅是工作量更少、调试方便,而且还有利于整体了解和把握算法。如果语言设计得好,大多数报表的数据源准备算法都可以在一屏内实现,整个算法过程一目了然。
应用耦合
报表的呈现式样是由报表工具绘制的模板来控制,报表模板一般以文件形式存放在文件系统中。如果数据准备采用自定义数据源实现,这部分代码将作为应用程序的一部分被一起编译和打包。呈现模板和数据集算法作为同一个报表的两个关键要素必须合理配合才能正常工作,但物理上却会分存于两处,甚至可能是不同人员开发的,这给修改维护报表带来麻烦,需要刻意去保持两处的一致性。
独立计算层的计算脚本和报表模板一样,都是解释执行的,脚本也可以文件形式与和报表模板放在一起,报表维护时很容易保证这两部分一致,这方面不存在应用耦合问题。
热切换
报表的数据集算法如果使用自定义数据源实现,那就会成为应用程序的一部分,发生修改时就需要和整个应用程序一起重新编译打包,并且在大多数情况时需要将应用停机后再重启。而报表是个业务稳定性相对较差的功能,经常会增加和修改,这样就会导致应用程序频繁重启。虽然Java等开发机制也支持热加载,但使用复杂,大多数应用程序员难以掌握。而且一旦加载后的程序就不会被清除,即使不再有用也会一直占据内存,热加载技术并不很合适应用于报表数据源。
类似地,热切换对于使用独立计算层的脚本也不再是问题,有报表修改只要修改呈现模板和相应的计算脚本。因为脚本是解释执行的,应用程序本身并不需要改变,也就没有必要停机重启。被修改的报表在访问时临时计算即可。
开发人员
使用Java等高级语言实现报表数据集准备时,需要在代码中引用数据库连接、基础类库等各种环境信息,还要了解和遵循整个应用程序的代码规范以保持协调,这常常是项目组中的专业程序员才能掌握的技能。而开发报表数据集只要了解数据结构和运算逻辑,其实用户方有不少技术人员都拥有这个能力,但苦于难以理解开发环境而很难自由实现新的报表。
有独立计算层时,报表开发需要的各种环境信息可以事先在应用程序中配置好,使用脚本编程时也不必关心整个应用的代码规范,报表开发人员只要关心数据结构和运算逻辑,可以用于开发报表的人员更多,以适应报表频繁修改的业务特性。