【案例】集算器在用友加速大数据报表
随着业务的发展,用友公司某项目的数据量越来越大。有些查询需要等待的时间也越来越长。我们针对其中一个比较典型场景,用集算器做了查询优化,查询等待时间从90秒缩短到1-2秒,充分体现了集算器的运算效率,使实际项目的查询性能得到大幅提升。
具体的技术方案如下:
原始SQL
查询涉及到的数据存储在Oracle数据库中,数据量有百万条。原有对应的sql如下:
selecta.paytime 支付时间,
c.parent_party_name 上级公司,
c.child_party_name 公司名称,
b.BANK_TYPE_SNAME 银行类别,
a.outacctname 付款户名,
a.dbtacc 付方账号,
a.crtnam 收方户名,
a.crtacc 收方账号,
a.buss_type 业务类型,
a.trsamt 支付金额
from ebank_log a
left join BD_BANK_TYPE b
on a.BANKTYPECODE = b.BANK_TYPE_CODE
left join RM_PARTY_RELATION c
on a.PK_CORP = c.CHILD_PARTY_ID
AND c.PARTY_VIEW_ID = '1000200700000000003'
where a.TRSAMT >= 50000
and (length(a.CRTNAM) <= 4 or proxy ='1')--对私支付
and instr(c.child_party_code, 'C00100S') =1--某省内机构
and a.paytime >= to_date('2016-01-01','yyyy-mm-dd')
and a.paytime < to_date('2017-02-25','yyyy-mm-dd')
其中ebank_log表100万条数据,BD_BANK_TYPE23条,RM_PARTY_RELATION 43万。SQL执行的时间非常慢,后来项目组采用用友内部的BI工具做了优化,仍然需要等待一分半钟。
集算器优化
采用集算器优化的思路是:将数据从数据库中导出成二进制的文件,采用润乾报表5.0+集算器的大报表功能,流式加载数据。
集算器的脚本如下:
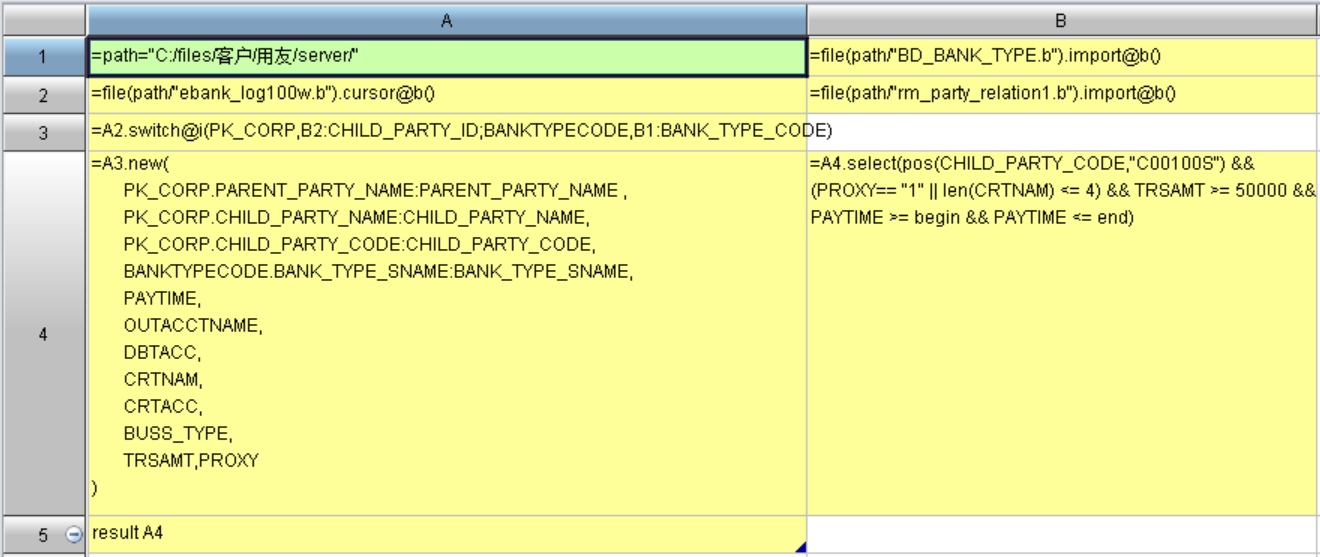
A2:采用游标的方式加载较大的表ebank_log。
B1、B2:采用全内存方式加载两个比较小的表。
A3:把游标的关联字段切换成两个较小表的引用记录。
A4:对游标重新构建成需要的字段。
B4:按照条件过滤游标。
A5:返回游标。
报表制作
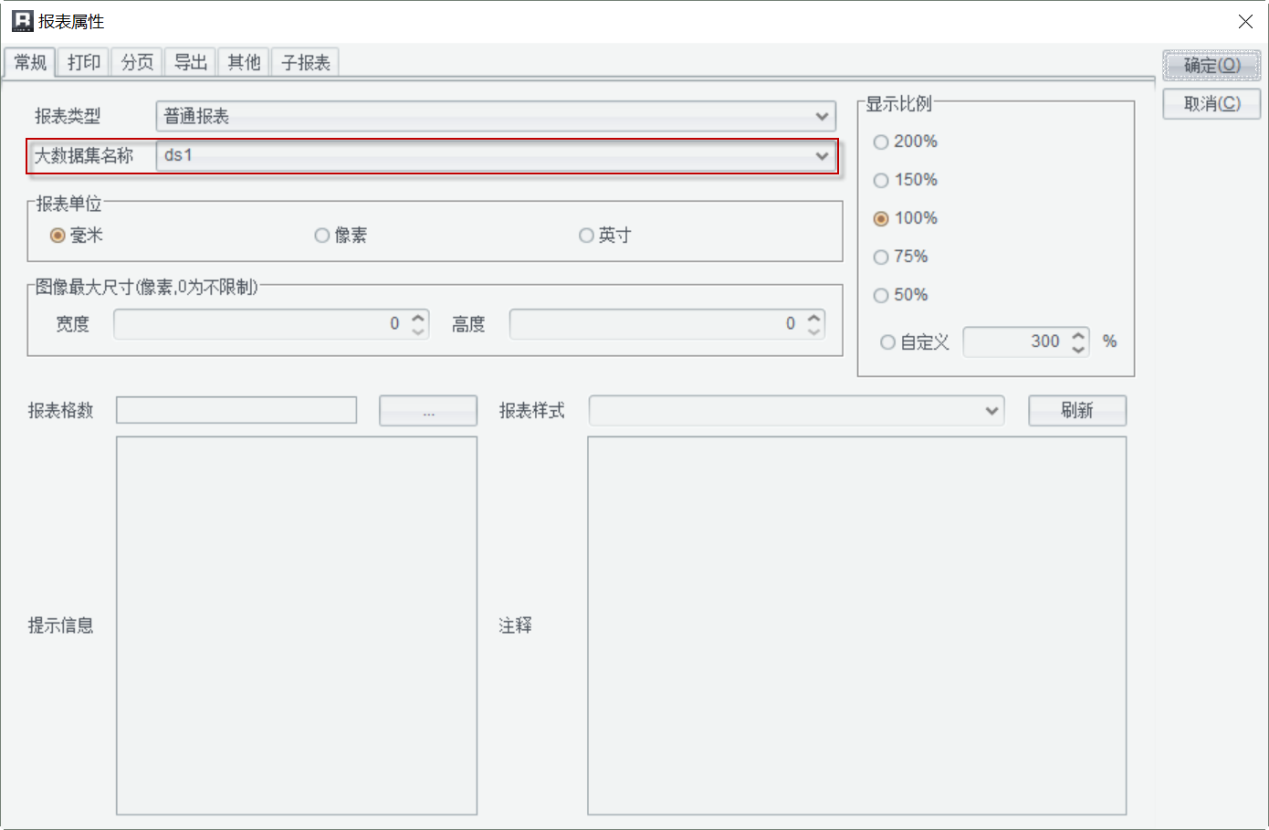
对应的报表模板如下图:

ds1调用上述集算器脚本,并且设置为大数据集:
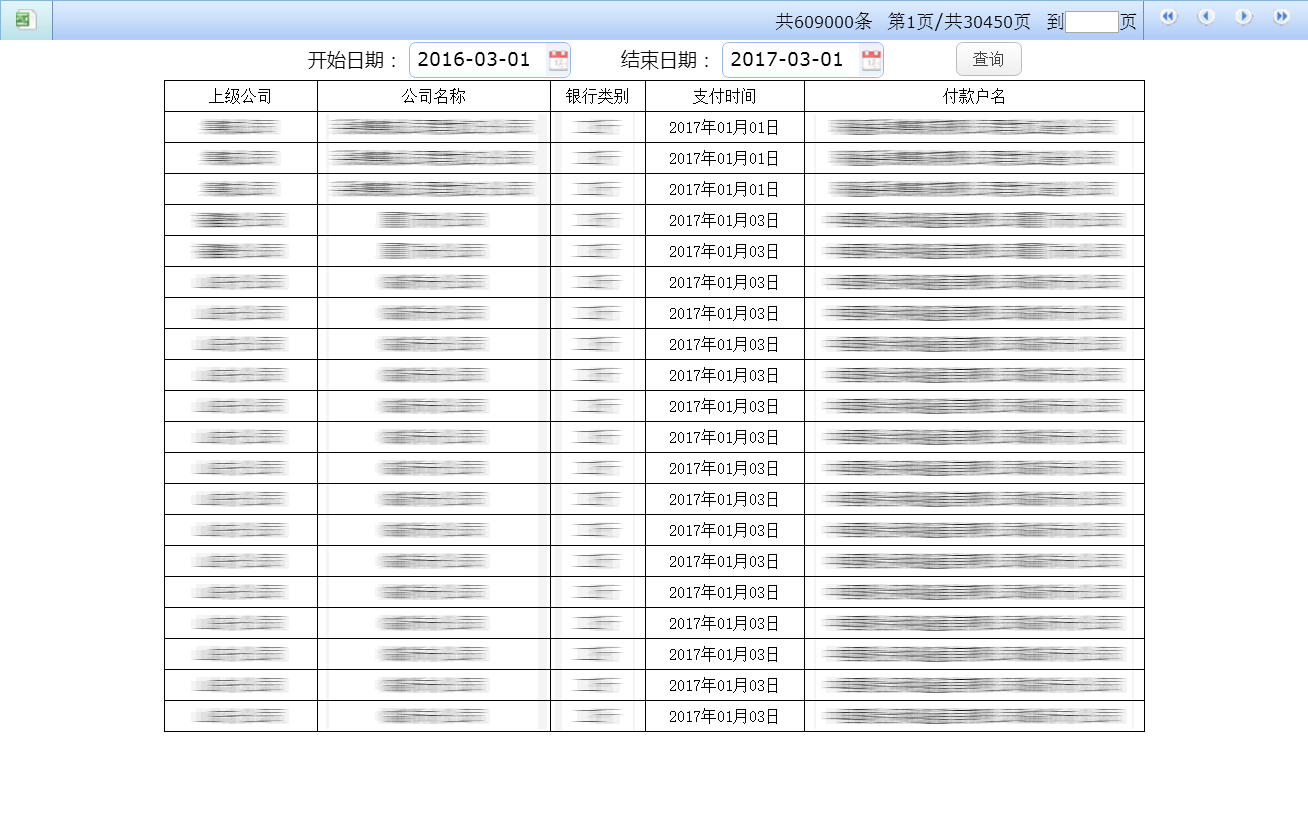
最后的查询结果网页如下图:
优化总结
大数据报表之所以能做到快速的响应,是因为采用了集算器的流式异步加载数据的机制:
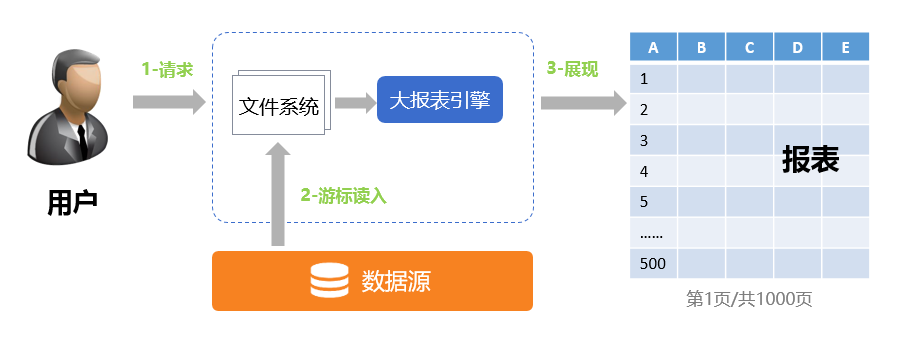
从上图可以看出,用户请求大报表之后,集算器(大报表引擎)只加载少量数据,形成最初的几页展现给用户。在用户查看这几页数据的时候,集算器同时会加载剩余的数据到二进制文件中,等到用户翻页的时候再从本地二进制文件中读取数据展现。这样既能保证快速的响应,又能避免加载大量数据造成内存溢出。