【产品案例】集算器助力某省信访大数据
Hadoop大数据平台是某省信访局2017年的重点项目,该平台以数据采集、数据存储、数据计算为中间件,下接信访系统、数据接口文件、外部数据等数据源,上接即席查询、统计报表、管理驾驶舱等数据应用,从而实现关键指标展示、社会治理预警、网络舆情分析等具体业务。
整体结构如下:
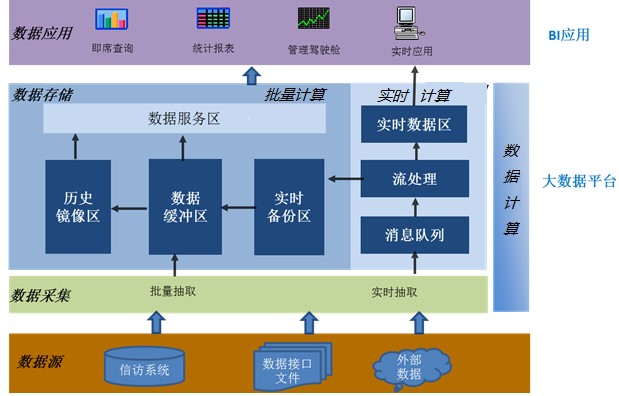
该大数据项目是各省信访局的参照标杆和国家级项目的孵化器,其战略意义深远。但本项目实施过程中存在着数据源多样,性能要求高、业务逻辑复杂等难点,具体如下:
- 数据源多样
本项目数据来源各式各样,按业务渠道的不同,可分为信访系统、数据接口文件、外部数据;按数据类型的不同,可分为结构化数据(信访资源编目库、信访公共基础库)、半结构化数据(文件、Http流)、非结构化数据(信访图片、监控视频)。按访问接口可进一步细分,文件可分为日志文件、Excel文件、xml文件;Http流分为Json、 WebService;数据库分为支持ANSI新标准的Oracle、SQLSERVER,支持旧标准的MYSQL,以及非ANSI标准的HIVE(外部大数仓)。
非结构化数据可直接复制到平台的非结构化大数据仓库(HDFS),不存在难点。但结构化和半结构化数据要经过ETL加工过程,存储在结构化大数据仓库(HIVE)之后,才能被外部应用统一调用,这就要求ETL工具具备丰富的访问接口。现实情况是:大数据ETL工具(如Sqoop、kettle)接口有限,对日志和关系型数据库支持较好,其他数据源只能用高级语言访问(如JAVA API),或导入临时库再ETL(即LETL)。
数据源之间存在业务关联,比如资源编目库要根据公共基础库过滤,或者Excel文件要和数据库关联,符合条件的合法数据才会存入HIVE,这就要求ETL工具具备多数据源混合计算的能力。现实情况是:大数据ETL工具缺乏直接混算能力,只能用JAVA硬编码间接混算。
- 性能要求高
大数据平台的特点就是数据量大、计算量大、访问量大,性能自然是核心指标之一。在整个平台中,非结构化数据虽然占据95%,但这类数据只需以文件为单位原样复制,几乎没有计算要求。相反,HIVE中的结构化数据虽然只占5%,但这类数据需要以记录字段为单位进行计算,粒度比文件小得多,因此总体计算量反而占到95%。
不论即席查询还是统计报表,不论数据分析还是监控预测,所有的外部应用都要基于结构化数据进行计算。如果计算性能太差,无疑会大大降低用户体验,比如长时间的查询等待,比如延迟推送统计结果,或者只能查看预生成的死数据,有时还会造成系统崩溃。
采用HANA、Teradada或Oracle TimesTen可有效提高性能,但投入成本是天文数字,而GreenPlum稳定性太差,不适合政府行业,这里都不做讨论。要想提高结构化数据的计算性能,切实可行的方法有三种:分布式计算、多线程计算、算法优化。
现实情况是:大数据计算工具(比如SPARK on Hive)拥有良好的分布式计算能力,但在多线程计算和算法优化上还做得远远不够。在单机多线程计算方面,大数据计算工具性能只有传统数据库(Oracle)的十分之一到五分之一。在算法优化方面,大数据计算工具一直在模仿传统数据库,而传统数据库的算法依据关系代数理论,自上世纪七十年代起就已经不再变化,优化空间早已走到尽头。
- 业务逻辑复杂
源数据ETL到大数据平台,大数据平台对外提供数据服务,这两处涉及到大量计算,部分业务逻辑比较复杂。
根据业务逻辑由易到难的程度,大数据ETL工具分别提供了SQL\存储过程\Perl\java等方法,工作量也按这个顺序由小到大排列。其中SQL\存储过程内置结构化计算函数,工作量不大,但后两者要自己实现底层函数,工作量比前两者大百倍。传统数据平台(数仓)之所以建设工期漫漫无期,主要就是因为后两者导致的。大数据ETL工具更多涉及半结构数据和多源混算,只能用Perl\java解决,因此工作量更大。
大数据平台对外提供十余种数据服务,每种服务包含几十(分析应用)到几百(报表应用)种不同的算法,其中业务逻辑较复杂的算法约占10%,典型的比如:根据信访态势、社会环境、网络舆情三方数据,先计算风险因素的变动趋势,再计算各种风险状态偏离预警线的强弱程度。此类算法在传统数仓中需用新标准SQL(比如支持ANSI2003的Oracle)实现。但大数据计算工具计算能力较差,尚达不到旧标准SQL,更加不支持新标准,只能用工作量巨大的JAVA代码实现。事实上,以往的大数据平台遇到复杂业务逻辑时,通常会把数据抽到Oracle中计算,这也是大数据平台华而不实难以落地的根本原因。
数据源多样,性能要求高、业务逻辑复杂,这三大难点如同暗藏的冰山,一旦解决不好,就会使大数据平台这艘旗舰之作沦为泰坦尼克。为了规避风险顺利实施,项目组引入了集算器。集算器是针对大数据平台的优化利器,支持多样数据源,可提高计算性能,并降低复杂算法工作量,适合解决本项目的难点。
集算器在结构图中位置如下:
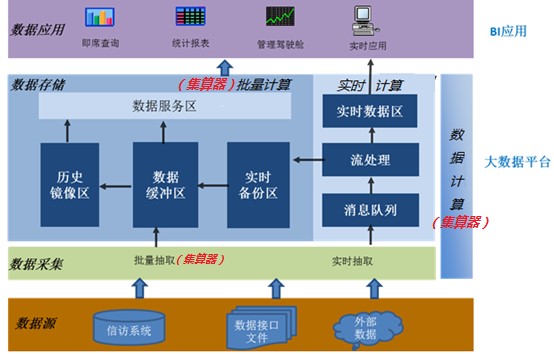
- 支持多样数据源
集算器接口丰富,不仅支持日志和关系型数据库,也直接支持WebService和json流,以及MongoDB、HBASE、阿里云OTS这类NOSQL数据库,还有HDFS文件、elasticSearch全文搜索引擎。对于尚不支持的小众数据源,只需自行开发新接口就能直接计算,而不必导入数据库再计算,更不必用JAVA实现计算过程。
集算器支持直接跨库跨源的混合计算,不再依靠JAVA硬编码。不论单源计算还是混合计算,集算器都提供了一致的计算语法,无需为迁移切换做改变。
- 提高计算性能
像其他大数据计算工具一样,集算器也支持分布式计算,但集算器的独到之处,在于多线程计算和算法优化。基于自主可控的多线程计算,集算器比其他大数据计算工具性能高50-100倍。基于新型离散数学理论,集算器对传统算法进行了大量优化,其计算性能超越传统数据库。
- 降低复杂算法工作量
对于半结构化计算和多源混算,其他大数据ETL工具需要硬编码完成,而集算器可直接支持,其中难度消弭无形,开发工作量因此大幅降低。
对于真正的复杂业务逻辑,由于集算器基于新型离散数学理论而构建,其计算能力强于新SQL标准,因此比Oracle或其他大数据工具更易实现。以往需要用JAVA实现的复杂算法,现在只需用集算器轻松解决,不仅比SQL更易书写,还具备分步调试的优点。
集算器如同破冰船,装备三大破冰利器:支持多数据源、提高计算性能、降低复杂算法工作量。有集算器的保驾护航,本项目的三座冰山被一一击破,大数据平台这艘旗舰之作才得以顺利航行。